一、背景
JMeter是一款非常不错的开源压力测试工具,但在使用过程中也会遇到比较多问题排查,例如:起压机(客户端)请求并发数无法达到既定目标量、报内存溢出错误、错误事务数过高;
JMeter有两种运行模式(GUI、非GUI),非GUI模式(命令行模式)占用内存资源较小;
分布式Jmeter解决单机硬件局限性。

(一)产品需求压测指标
- CPU:80%
- 内存使用率:50%
- 平均响应时间 :3秒
- 单次压测持续时间 :30min
- 场景:有无缓存等与产品确认相关指标
- 生产、内网
备注:
压测指标一般以BI部门提供线上真实数据作为参考依据。
如未有指标进行阶段性加压,来寻找当前起压机(客户端)的极限值。(内存数、并发数)
(二)测试资源
- 申请线上压测机器(linux、win server)
- 申请堡垒机、跳板机权限(IP白名单限制、绕过运维防御机制)
- 测试脚本构建
二、环境配置
(一)压测机
- JDK 1.8
- JMeter 5.2.1
- Linux CentOS 7.6
(1)JDK环境变量配置
下载JDK
wget -c http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz解压
tar -xf jdk-8u181-linux-x64.tar.gz假设JDK解压后文件存放在/home/lyc/test/jdk1.8.0_18
环境配置
vim /etc/profile加入JAVA_HOME、JRE_HOME、PATH、CLASSPATH
export JAVA_HOME=/home/lyc/test/jdk1.8.0_181
export JRE_HOME=/home/lyc/test/jdk1.8.0_181/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
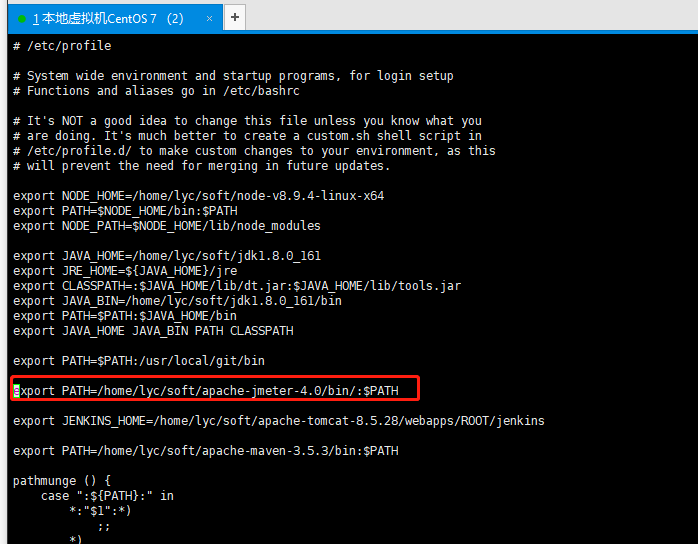
(2)JMeter环境变量配置
vim /etc/profile在末尾加入
export PATH=/home/lyc/test/apache-jmeter-5.2.1/bin/:$PATH按i进入编辑状态,按shift+zz,保存
(2)更新配置文件
source /etc/profile(3)检查版本
java --version
jmeter -v
三、分布式集群
(一)配置slave机
1.将所有slave机地址,配置到control机(master机)配置文件jmeter.properties 属性 remote_hosts
在controller机(master机)Jmeter目录的bin文件夹下,找到jmeter.properties,修改remote_hosts配置如下图,
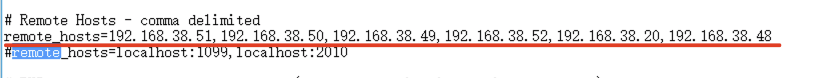
其中ip和port即为每台slave机的ip和端口逗号分隔;
controller机(master机)自身ip也配置上去,controller机(master机)自身也启动jmeter-server;
具体每台slave机的ip与端口,jmeter-server启动时控制台输出会显示,可以先启动jmeter-server;
2.关闭SSL
jmeter4.X之后controller机连接slave机,多了SSL身份验证环节,不想使用SSL,也可以进行关闭SLL,通过修改jmeter.properties(关闭RMI)
server.rmi.ssl.disable=true在remote_hosts下面加一个server.rmi.ssl.disable

controller机启动远程slave机,看看控制台是否start、end输出
内网压测禁用SSL,外网需要启动SSL,进行slave机和controller机身份验证
3.参数化csv文件
如果进行csv参数化,那么需要把参数文件在每台slave上拷一份且路径需要设置成一样。
(二)controller机远程启动slave机
说明:salve机无需放置测试脚本,只要controller机(master机)和slave机连接上后(配置remote_hosts),启动远程slave机自动同步controller机执行脚本。
1.非GUI模式
启动salve机执行脚本,并返回数据,同时生成聚合报告文件、日志等数据文件
jmeter -n -t 脚本名称.jmx -R 192.168.38.51,192.168.38.50,192.168.38.49,192.168.38.52,192.168.38.20,192.168.38.48 -l logfile.jtl -o testReport -j log -r -e参数说明:

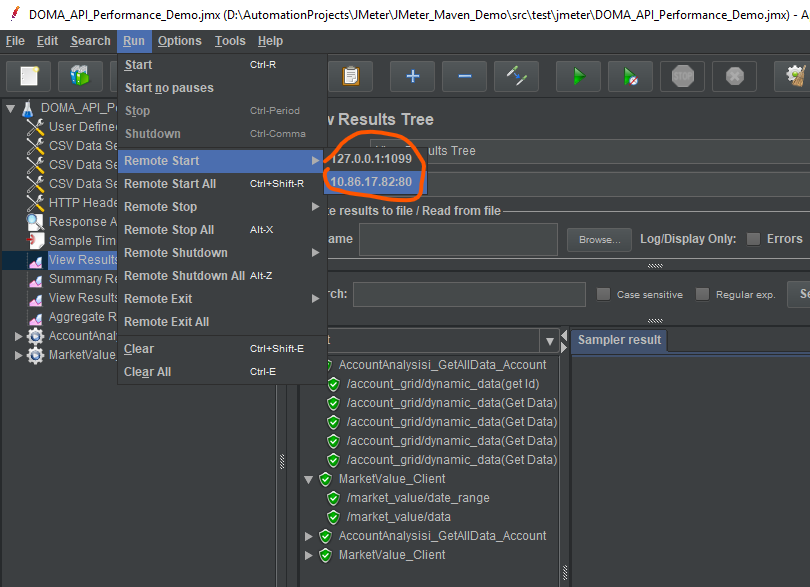
2.GUI模式
controller机是GUI模式启动远程脚本,可以通过菜单“运行-远程启动-slave机(IP+端口)”,点击远程启动,即可启动运行slave机器。
(二)数据汇总
1.汇总方式
(1)各台slave执行完成后,将结果传回给controller机,controller收集整合显示
此时在服务器上可看到控制台信息,在客户端通过监听器-聚合报告或察看结果数可看到执行结果


(三)报告
1.聚合报告:Aggregate Report
- Label:每个JMeter的element的Name值,例如:HTTP Request的Name
- Samples:发出请求数量。例如:第三行记录,模拟20个用户,循环100次,所以显示了2000
- Average:平均响应时间(单位:)默认是单个Request的平均响应时间,当使用了Transaction Controller时,也可以以Transaction为单位显示平均响应时间
- Median:中位数,也就是50%用户的响应时间
- 90%Line:90%用户的响应时间
- 95%Line:95%用户的响应时间
- 99%Line:99%用户的响应时间
- Min:最小响应时间
- Max:最大响应时间
- Error%:错误率,本次测试中出现错误的请求的数量/请求的总数
- Throughput:吞吐量。默认情况下标示每秒完成的请求数(具体单位如下图)
- KB/sec:每秒从服务器端接收到的数据量。

2.Dashboard report

(四)注意事项:
1.controller机、slave机 jmeter版本要一致。
2.slave机也需要配置JDK版本和controller机一致,同样配置java_home、jmeter_home
3.各slave机启动的线程数等于线程组中配置,不是均分线程组中的配置。
4.slave机启动后(jmeter-server)提示could not found ApacheJmeter_core.jar,说明slave机的Jmeter_home没有配置到bin上一级目录。
5.controller机、slave机之前可以通过ping ip来看是否互通。
6.堡垒机、跳板机要开权限。
7.关闭防火墙。
8.slave机启动后可看到绑定端口

四、常见问题:
(一)内存溢出 OutMemory
问题描述:
启动Jmeter脚本,运行一段时间,调试输出出现报错内存溢出,Jmeter内存占用过高,同样会导致测试结果的不准确性。
原因主要是当前客户端的硬件达不到当前所要测试指标条件(请求数、并发数过高),所以要用分布式jmeter来解决,分散压测指标到多个机器资源上面!
解决办法:
(1)调整jmeter占用内存配置
注意:默认Jmeter占用硬件内存资源256MB、512M,根据采坑经验,heap最多设置为物理内存的一半,默认设置为256MB、512M,如果heap超过物理内存的一半,运行Jmeter会慢仍会内存溢出,原因Java比较吃内存,占CPU。
注意:JDK版本必须是64位,才可以使Jmeter占用内容提高到2048,JDK32位版本,Jmeter虚拟内存占用仅能提到1500m。
Linux修改jmeter.sh文件,windows修改jmeter.bat
Jmeter 5.1之前版本,修改方式:
set HEAP=-Xms256m -Xmx256m
set NEW=-XX:NewSize=128m -XX:MaxNewSize=128m128m改为512m或1024m
set HEAP=-Xms256m -Xmx1024m
set NEW=-XX:NewSize=128m -XX:MaxNewSize=512m
Jmeter 5.1之后版本,修改方式:
【linux】
修改jmeter.sh文件
找到定义HEAP行位置,把256改512或1024,根据当前硬件内存资源来修改()

【windows】
修改jmeter.bat文件

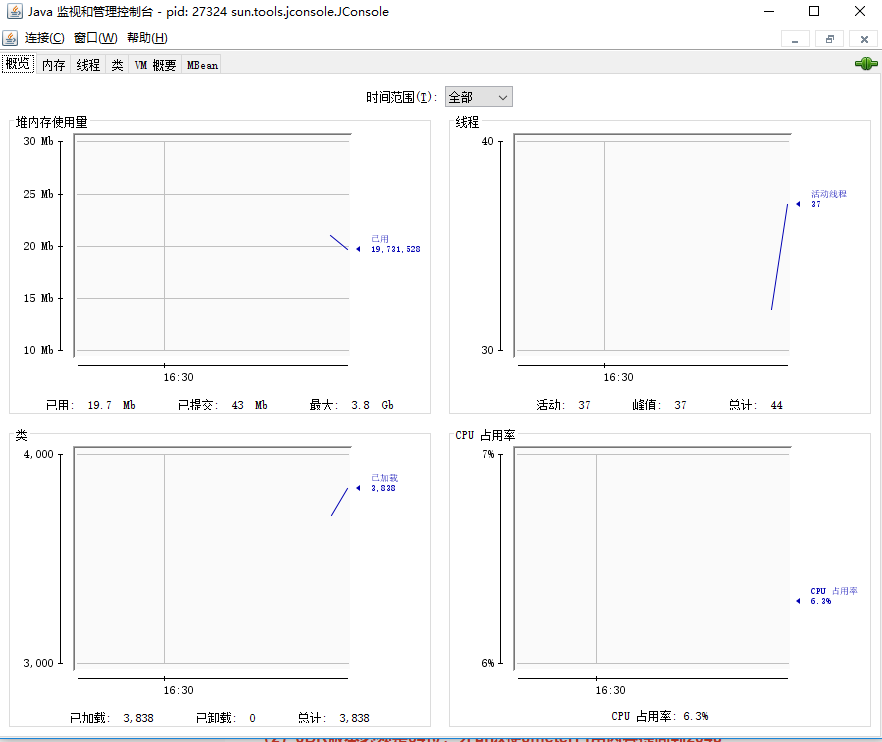
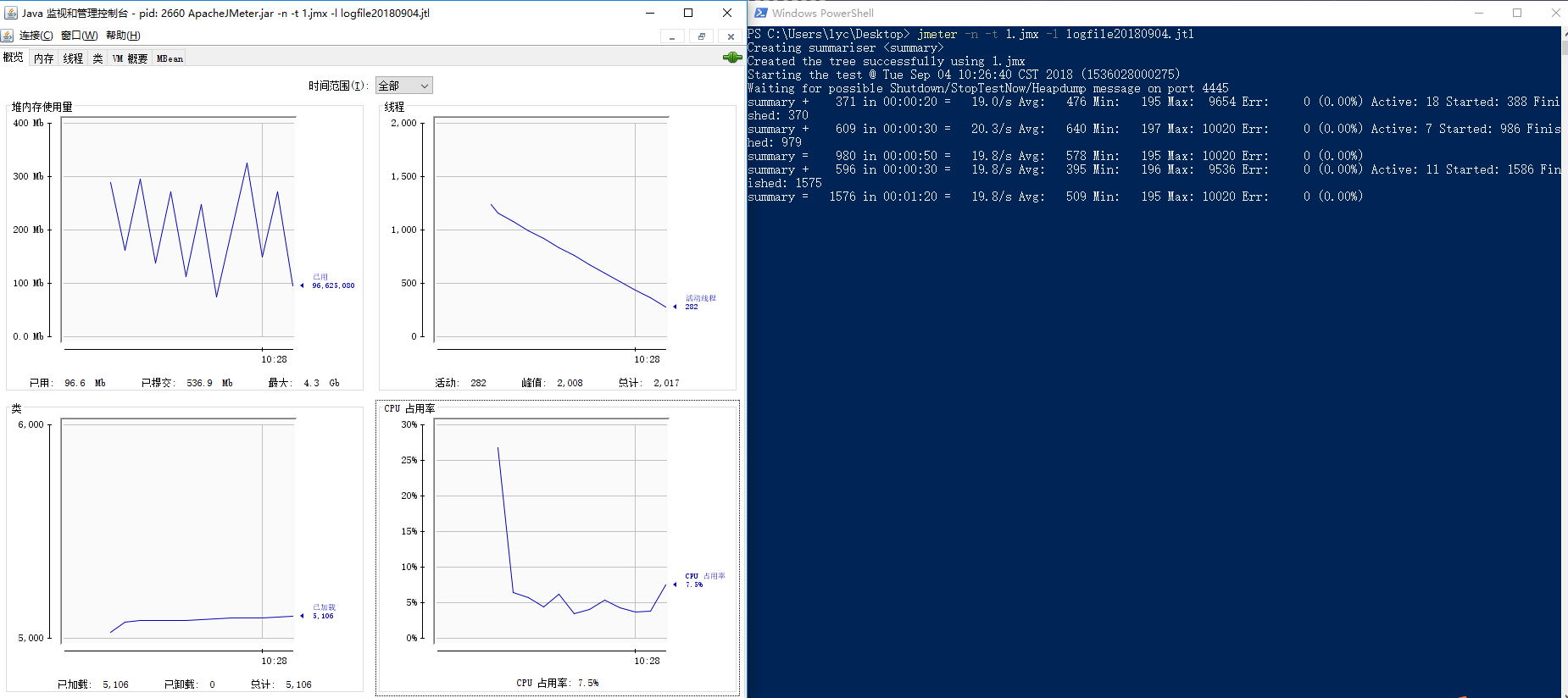
通过JDK Jconsole工具查看jmeter是否配置成功

(2)调整你的脚本,进行并发测试的时候,分布式jmeter + 非GUI模式,改用用命令行来测试。
(3)关闭不必要的日志信息,比如结果树,勾选记录失败日志。
【观察结果树】

【聚合报告】

(二)修改内存了,但启动jmeter控制台还是显示默认值
问题描述:
通过上一步修改了jmeter默认占用内存配置值,但是重启jmeter后dos窗口调试输出内存占用没有改变,仍然是256m
原因是控制台调试输出是jmeter默认值,而不是手动修改的那个内存占用参数HEAP值

解决办法:
通过JDK内存工具查看jmeter当前占用内存范围,来判断修改内存配置是否生效
【windows】

【linux、mac】
sh Jconsole.sh
(三)查看结果树的数据没有显示全
问题描述:
用jmeter做接口测试时,查看结果树的数据没有显示全,给出下面的错误提示
Response too large to be displayed. Size: 1349830 > Max: 204800
解决办法:
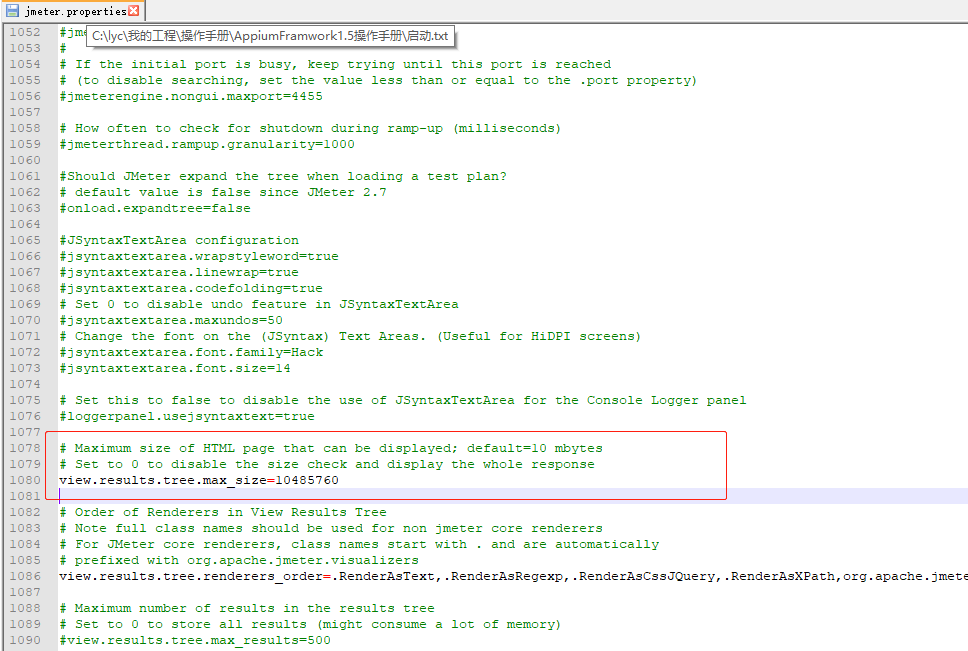
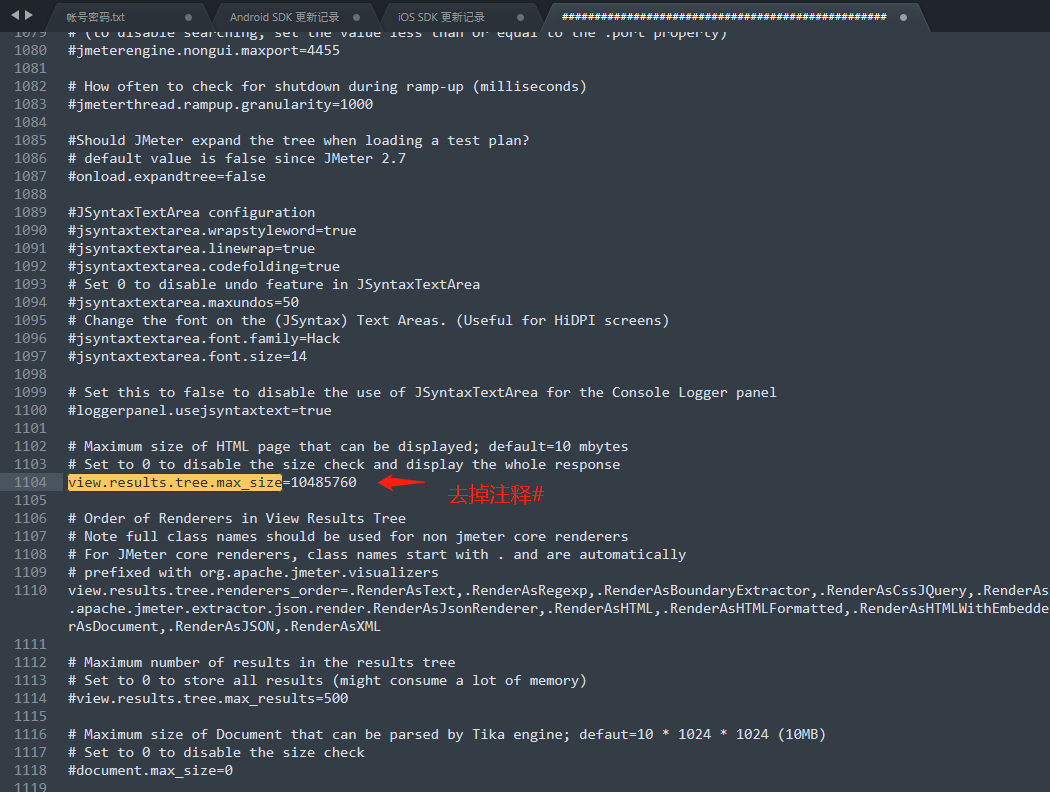
修改jmeter.properties文件,将view.results.tree.max_size的值修改大一些,比实际的Size大。
例如:
view.results.tree.max_size=2349830然后重启jmeter,再次请求,响应结果正常显示了
【windows】
(1)进入apache-jmeter目录bin下
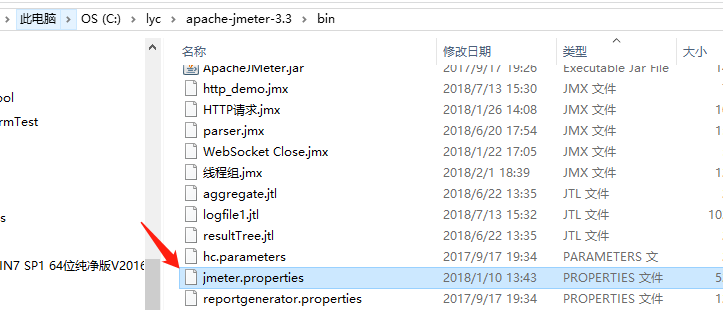
编辑jmeter.properties文件中view.results.tree.max.size
【linux】
(1)进入apache-jmeter目录bin下
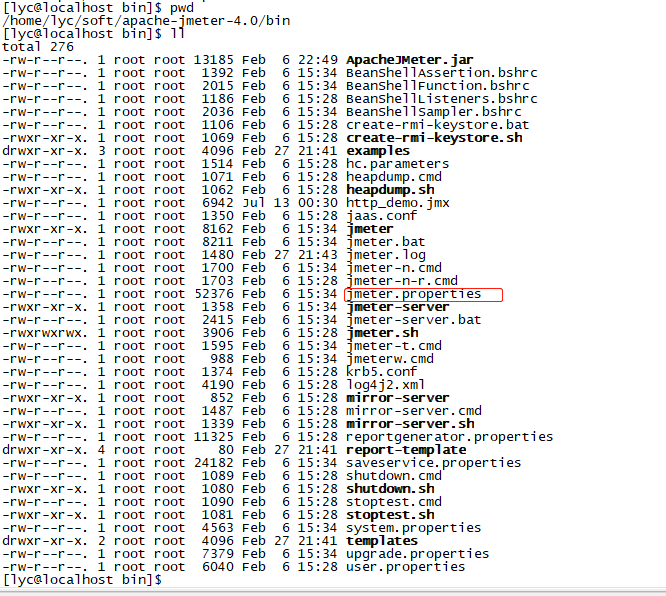
vim jmeter.properties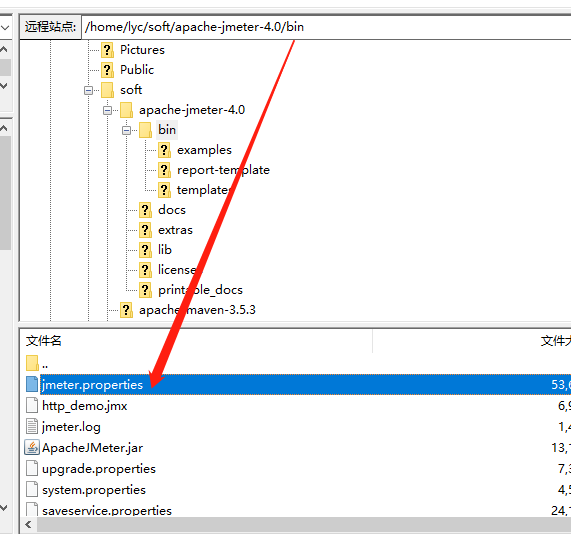
(四)查看结果树的数据没有显示全
问题描述:
用jmeter做接口测试时,查看结果树的数据没有显示全,给出下面的错误提示
Response too large to be displayed. Size: 1349830 > Max: 204800
解决办法:
修改jmeter.properties文件,将view.results.tree.max_size的值修改大一些,比实际的Size大。
例如:view.results.tree.max_size=2349830
然后重启jmeter,再次请求,响应结果正常显示了
【windows】
(1)进入apache-jmeter目录bin下
编辑jmeter.properties文件中view.results.tree.max.size
【linux】
(1)进入apache-jmeter目录bin下
vim jmeter.properties
C:\Program Files\Java\jdk1.8.0_161\bin下 jconsole
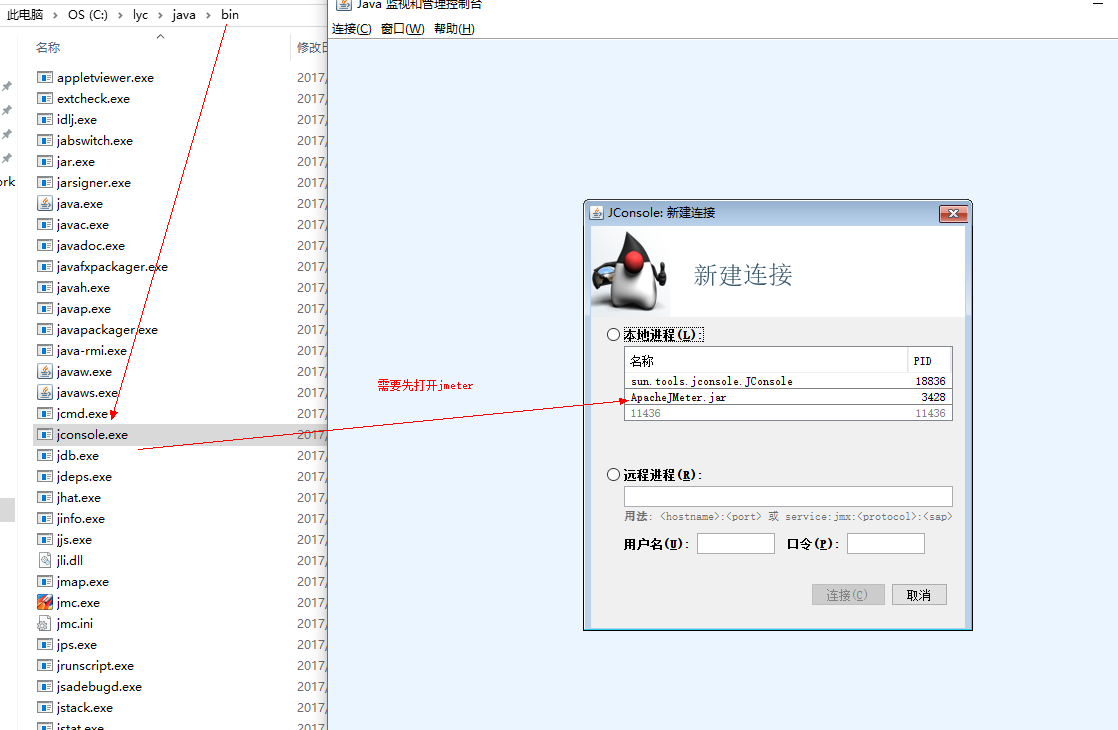
本地进程:选择要监控的进程。
VM概要,查看虚拟内存修改是否成功 -Xms 512m -Xmx2048m 最小使用内存和最大使用内存
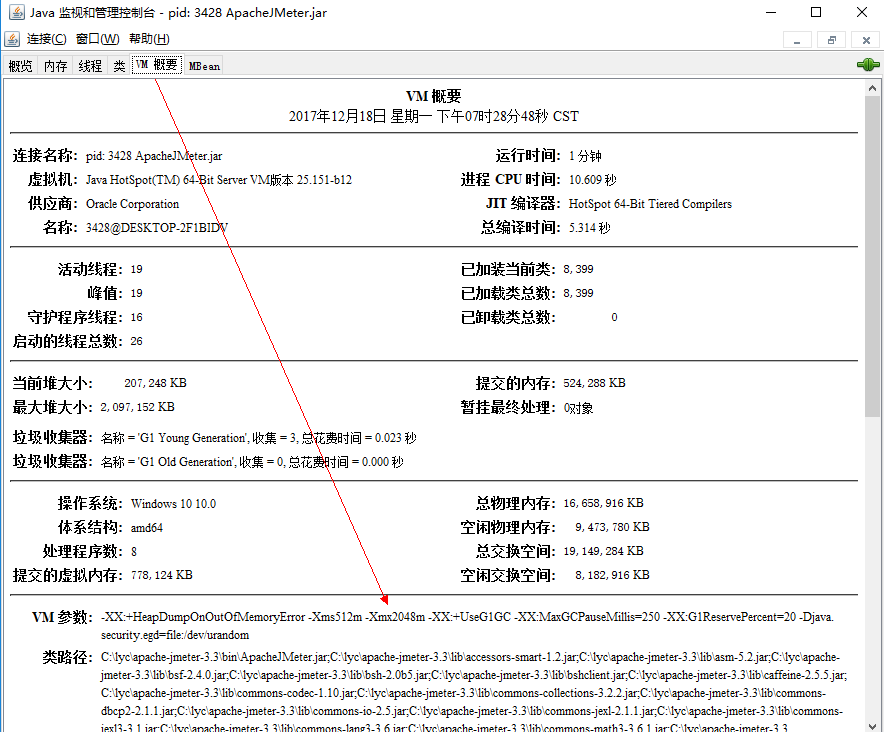
到此说明修改成功,dos窗口显示仍是512m可以忽略
打开jdk jconsole vm概述 查看当前分配最大可用内存
(五)查看linux内存消耗情况
1.查看linux总内存
free参数说明:
(1) free命令默认是以kb为单位显示的,可以用free -m 用Mb单位来显示。
(2) Mem行 : total = used + free 其中buffers和cached虽然计算在used内, 但其实为可用内存。
(3) Mem下一行:used为真实已占内存,free为真实可用内存。
(4)Swap:内存交换区的使用情况
2.查看内存占用,前五进程
ps auxw | head -1;ps auxw|sort -rn -k4|head -5(六)jmeter引入java jar包调用函数
1.
2.
(七)自动生成测试报告Apache Jmeter Dashboard report
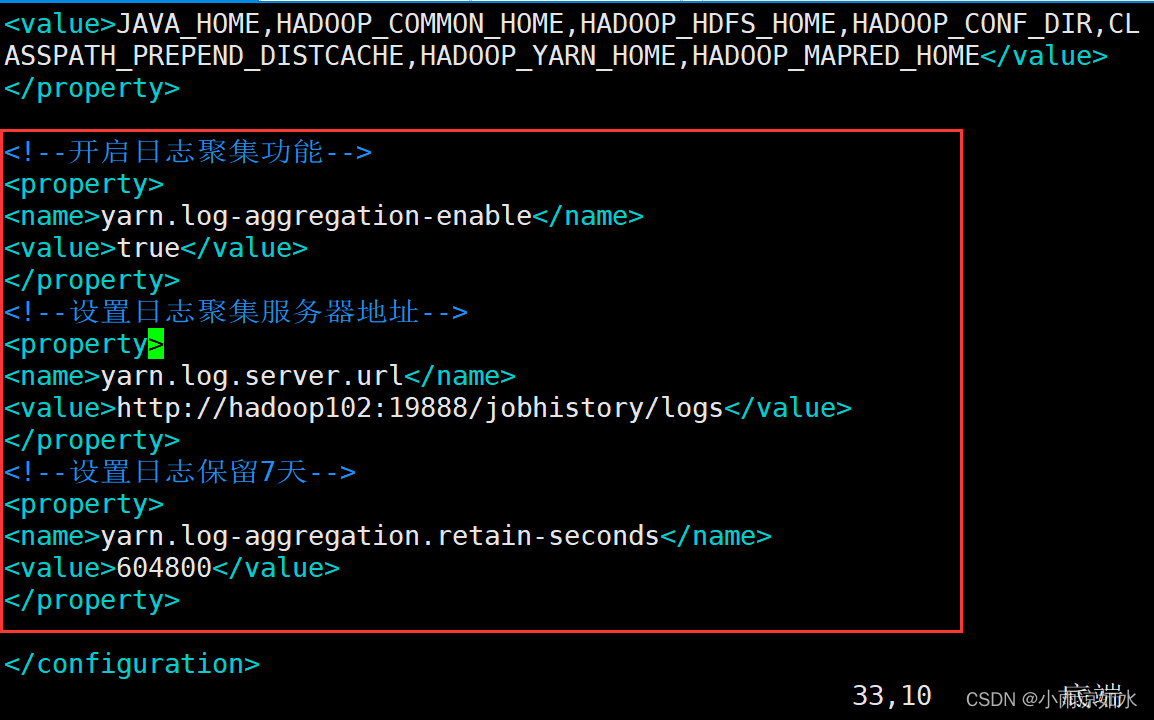
1.根据官网的配置,需要在jmeter.properties配置如下几个参数
https://jmeter.apache.org/usermanual/generating-dashboard.html


2.生成报告格式-l jtl改为csv
jmeter -n -t Get.jmx -l testResult.csv -e -o testReport

(八)执行jmx文件,报错missing class com.thoughtworks.xstream.converters.ConversionExceptions
问题描述:
执行非GUI模式,控制台报错“rror in NonGUIDriver java.lang.IllegalArgumentException: Problem loading XML from:'/Users/liyinchi/TestTool/apache-jmeter-5.2.1/Get.jmx', missing class com.thoughtworks.xstream.converters.ConversionException”

解决办法:
部分元件,像是上图json断言无法进行转换
其他可能原因缺少依赖的插件包
下载缺少的插件包,将本地的插件包传入执行jmx文件的机器。
查看具体缺少哪一个插件包的方法:
(1)引入jmx文件,如果缺少插件包会有如下提示:
(2)如果没有提示,则查看已经安装了哪些插件包,拷贝执行机器缺少的包(ext存放插件包)

(九)执行sh jmeter.sh 报command not found
问题描述:
jmeter环境配置问题
解决办法:
执行chmod 777 jmeter.sh授权,再用 sh jmeter.sh -v 来检测命令是否可用
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin)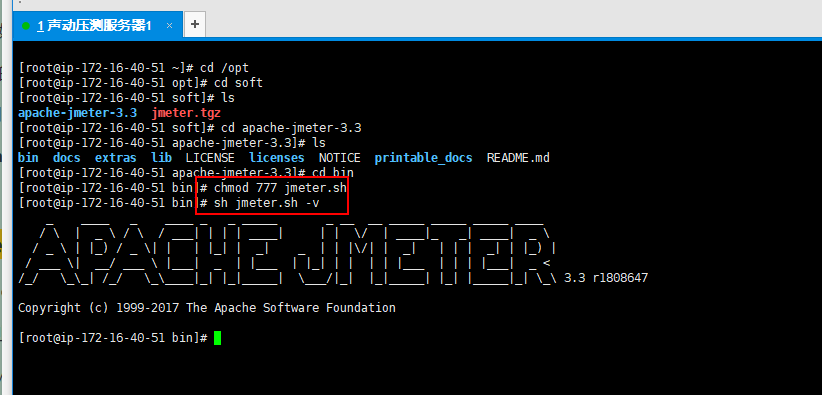
(十)报错:java.net.BindException: Address already in use: connect
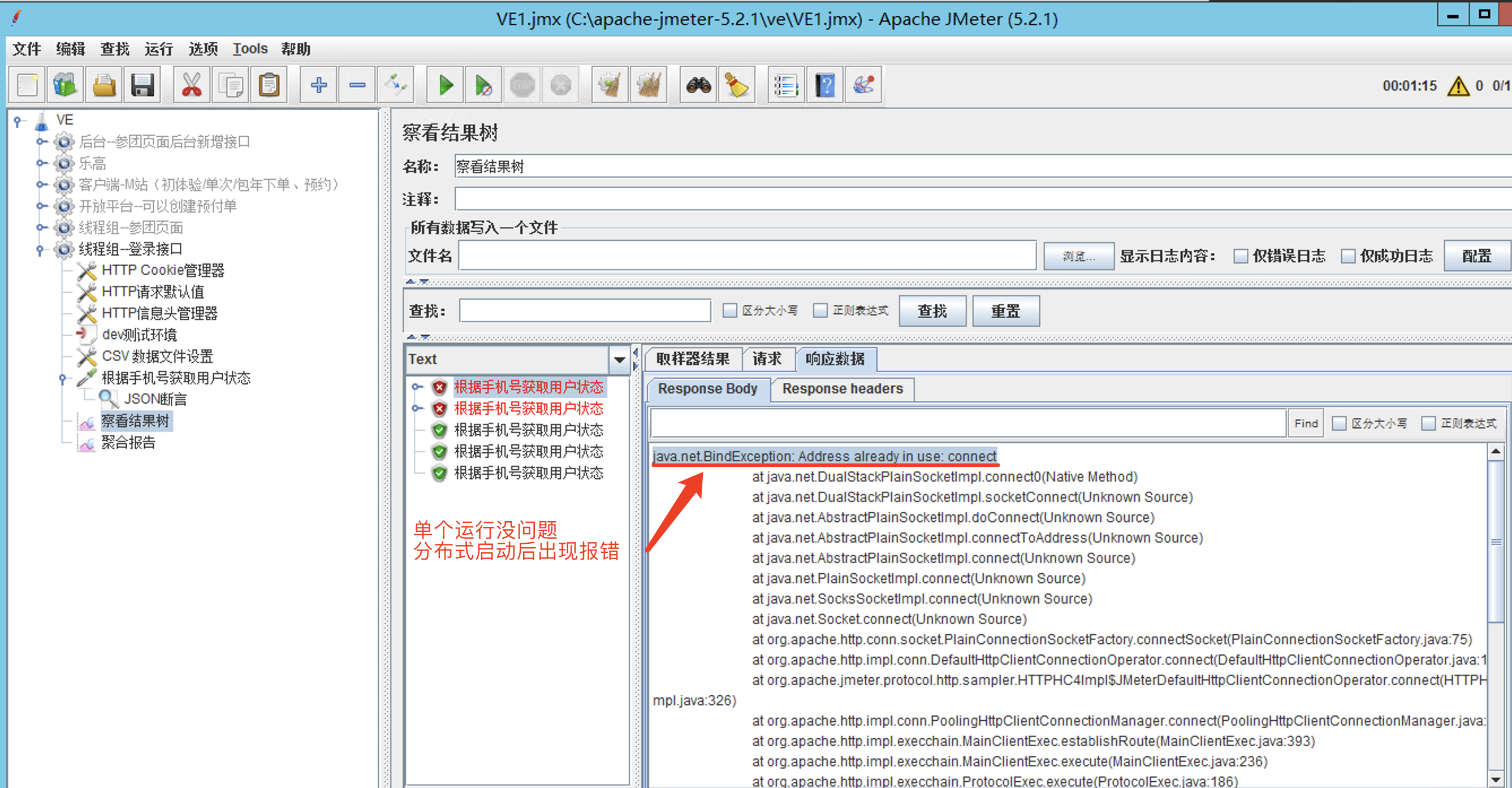
排除问题:
首先先查看服务器的日志,发现没有报错。
然后查看nginx数据,发现请求数和测试发出的请求数不一致,服务器接收到的少,就想到丢失请求。
后来经过查找资料了解是windows 机器的问题,
原因:windows提供给TCP/IP链接的端口为 1024-5000,并且要四分钟来循环回收它们,就导致我们在短时间内跑大量的请求时将端口占满了,导致如上报错。
解决办法(在jmeter所在服务器操作):
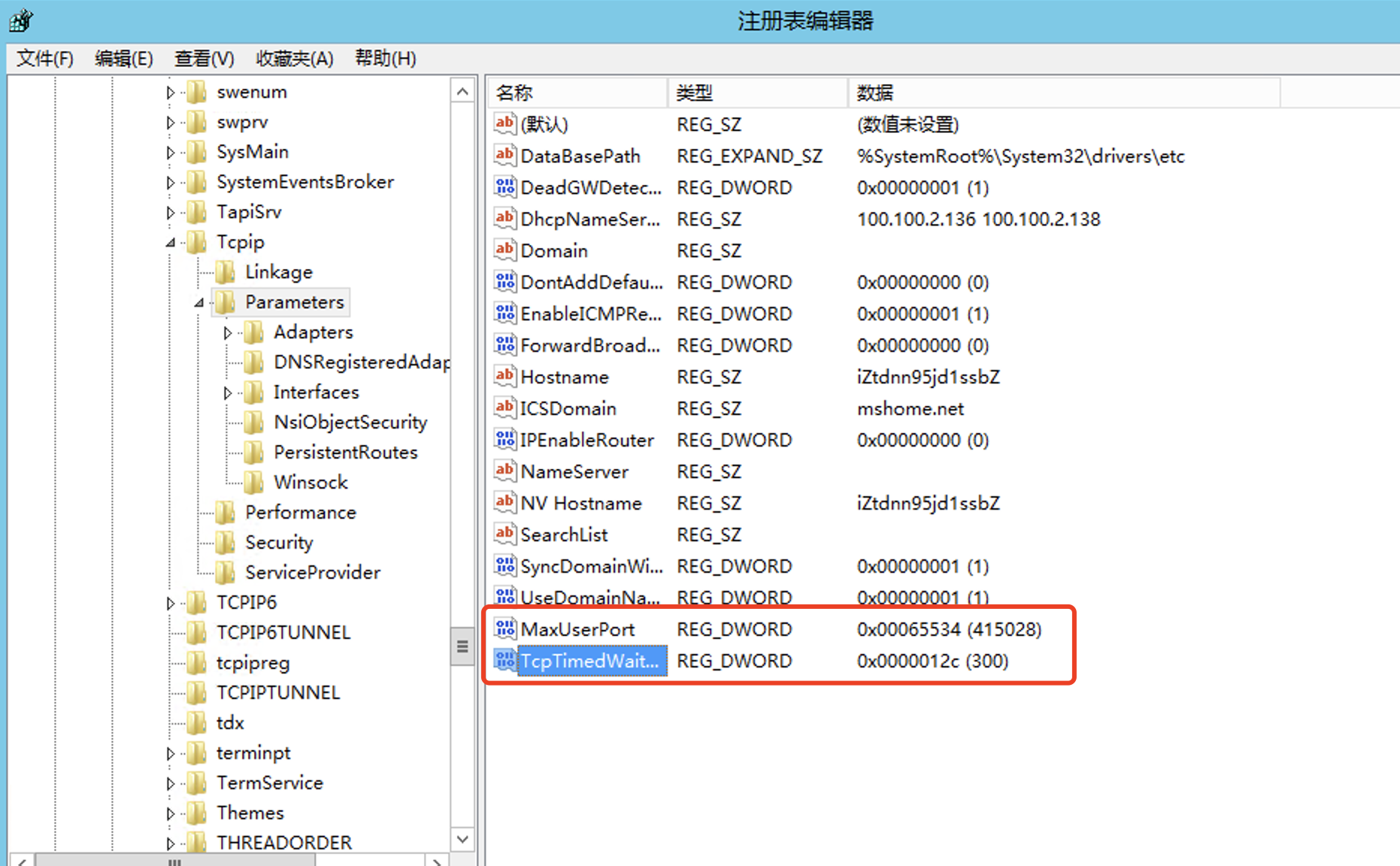
1.cmd中输入regedit命令打开注册表;
2.在 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters右键Parameters;
3.添加一个新的DWORD,名字为MaxUserPort;
4.然后双击MaxUserPort,输入数值数据为65534,基数选择十进制;
5.完成以上操作,务必重启机器,问题解决。