目录
一 关联分析的应用
二 关联分析定义
关联分析(又称关联挖掘)
常见关系分类
四 基本原理
编辑
五 常用算法
5.1 先验算法Apriori
5.2 FP-Growth算法
一 关联分析的应用
- 在美国国会投票记录中发现关联规则
- 发现毒蘑菇的相似特征
- 在Twitter源中发现一些共现词
- 从网站点击流中挖掘流行趋势,挖掘哪些广泛被用户浏览
二 关联分析定义
关联分析(又称关联挖掘)
在 交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构 。
或者 说,关联分析是发现交易数据库中不同商品(项)之间的联系。
常见关系分类
简单关联关系:没有 共同 属性的事物的组合,组合元素会较大概率同时出现 eg:牛奶和面包
序列关联关系: 事物的出现,很大概率上,会在时间上以一定的先后顺序发生 eg:手机和手机壳
三 基本概念
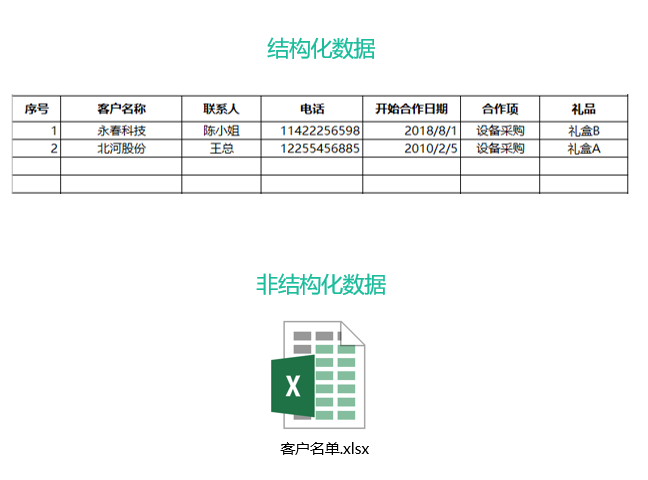
项集(Itemset):令 I = { i1,i2,……,in } 是购物篮数据中的所有项的集合,T = { t1,t2,……,td } 是所有事务的集合。每个事务 ti 包含的项集都是 I 的子集。包含0个或多个项的集合称为项集。
k-项集:如果一个项集包含 k 个项,称其为k-项集。
支持 度 计数 (Support count):包含特定项集的事务个数为支持度计数, 用 s 表示。 在数学上,项集 X 的支持度计数 s ( X ) 可以表示为 :
支持 度 (Support ):包含某项集的事务数与总事务数的比值称为该项集的支持度, 用 s 表示 。 支持度衡量的是某项集(即 构成 该项集的各个 事件 ) 同时 出现的概率 。
频繁项集(Frequent ItemSet):是指能够 满足支持 度阈值 ( minSup )的所有 项集支持度阈值是人为指定的一个 数值
候选项集:未经支持度检验的项集
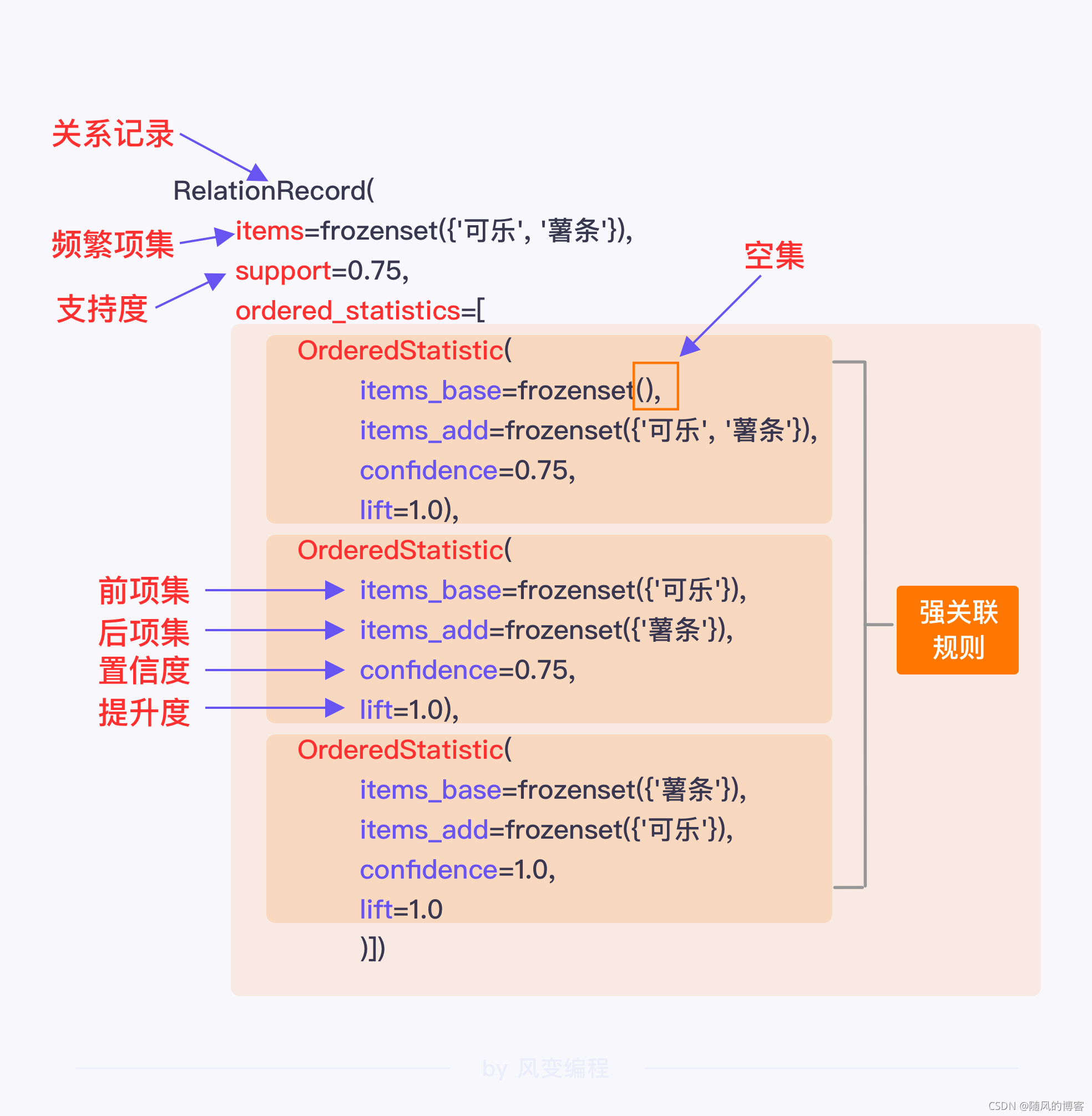
置信度(confidence):置信度揭示了 X 出现 时 , Y 是否 一定会出现,如果出现则其大概有多大的可能出现 。如果置信度为100%,则说 明了 X 出现 时 , Y 一定出现。那么,对这种情况而言, 假设 X 和 Y 是 市场上的两种商品,就没有理由不进行捆绑销售 了
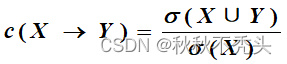
关联规则(Association Rule)是形如 X → Y 的蕴含表达式,其中 X 和 Y 是不相交的项集,即有 X ∩ Y = Ø。
关联规则的强度可以用它的支持度s 和置信度c 来度量。
支持度确定规则可以用于给定数据集的频繁程度,而置信度确定 Y 在包含 X 的事务中出现的频繁程度。
四 基本原理

参考书籍 《数据挖掘导论》、《数据挖掘原理与应用》