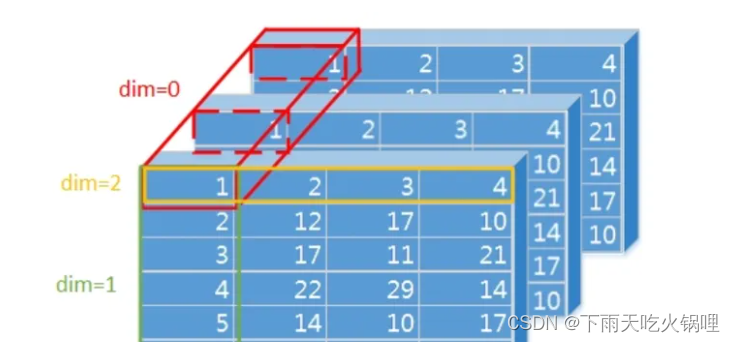
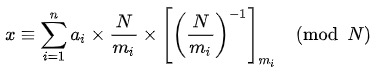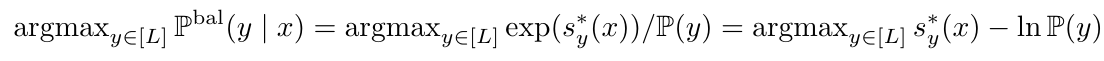说明:使用neo4j算法库时需引入跟neo4j数据库对应的算法库插件或自定义算法库
1.简介
欧几里德距离算法原理是计算n维坐标系中点与点之间地距离,如在三维坐标系中点A(p1,p2,p3),点B(q1,q2,q3),两个点之间得距离则为 :,
如果在n维坐标系中,两个点得距离则变为:
根据以上特性拓展:距离越小则A点和B点重合度越高,由此可衍生出A点和B点在n维空间中距离相似度公式为:
neo4j自带算法包提供了欧几里得相似度算法得函数和过程,函数适合少量数据计算,过程适合批量数据得计算
2.使用场景
何时使用欧几里得算法呢,我们可以使用欧几里的距离算法来计算两件事之间得相似性,然后,我们可能会将相似性用作推荐查询得一部分,比如用户A和用户B之间共同爱看得电影,比如根据用户A和用户B共同出入得场所,判定用户A和B职业预测,用户A和用户B共同好友,实现可能好友推荐
3.neo4j中欧几里得函数使用示例
在neo4j中存在algo.similarity.euclideanDistance计算距离函数,也存在algo.similarity.euclidean计算相似度得函数
1.计算两个硬编码列表距离
RETURN algo.similarity.euclideanDistance([3,8,7,5,2,9], [10,8,6,6,4,5]) AS similarity
结果:8.426149773176359
2.计算两个硬编码列表相似度
ETURN algo.similarity.euclidean([3,8,7,5,2,9], [10,8,6,6,4,5]) AS similarity
结果:0.1060878539025194
3.我们还可以使用它来计算节点关联节点相似性
初始化数据
MERGE (french:Cuisine {name:'French'})
MERGE (italian:Cuisine {name:'Italian'})
MERGE (indian:Cuisine {name:'Indian'})
MERGE (lebanese:Cuisine {name:'Lebanese'})
MERGE (portuguese:Cuisine {name:'Portuguese'})
MERGE (british:Cuisine {name:'British'})
MERGE (mauritian:Cuisine {name:'Mauritian'})MERGE (zhen:Person {name: "Zhen"})
MERGE (praveena:Person {name: "Praveena"})
MERGE (michael:Person {name: "Michael"})
MERGE (arya:Person {name: "Arya"})
MERGE (karin:Person {name: "Karin"})MERGE (praveena)-[:LIKES {score: 9}]->(indian)
MERGE (praveena)-[:LIKES {score: 7}]->(portuguese)
MERGE (praveena)-[:LIKES {score: 8}]->(british)
MERGE (praveena)-[:LIKES {score: 1}]->(mauritian)MERGE (zhen)-[:LIKES {score: 10}]->(french)
MERGE (zhen)-[:LIKES {score: 6}]->(indian)
MERGE (zhen)-[:LIKES {score: 2}]->(british)MERGE (michael)-[:LIKES {score: 8}]->(french)
MERGE (michael)-[:LIKES {score: 7}]->(italian)
MERGE (michael)-[:LIKES {score: 9}]->(indian)
MERGE (michael)-[:LIKES {score: 3}]->(portuguese)MERGE (arya)-[:LIKES {score: 10}]->(lebanese)
MERGE (arya)-[:LIKES {score: 10}]->(italian)
MERGE (arya)-[:LIKES {score: 7}]->(portuguese)
MERGE (arya)-[:LIKES {score: 9}]->(mauritian)MERGE (karin)-[:LIKES {score: 9}]->(lebanese)
MERGE (karin)-[:LIKES {score: 7}]->(italian)
MERGE (karin)-[:LIKES {score: 10}]->(portuguese)查询'Zhen'和Praveena喜好相似度:
MATCH (p1:Person {name: 'Zhen'})-[likes1:LIKES]->(cuisine) MATCH (p2:Person {name: "Praveena"})-[likes2:LIKES]->(cuisine) RETURN p1.name AS from,p2.name AS to,algo.similarity.euclidean(collect(likes1.score), collect(likes2.score)) AS similarity结果:

4.以下将返回Zhen和其它有共同美食爱好得欧几里得相似度
MATCH (p1:Person {name: 'Zhen'})-[likes1:LIKES]->(cuisine) MATCH (p2:Person)-[likes2:LIKES]->(cuisine) WHERE p2 <> p1 RETURN p1.name AS from,p2.name AS to,algo.similarity.euclidean(collect(likes1.score), collect(likes2.score)) AS similarity ORDER BY similarity DESC结果:

4.源码解析
algo.similarity.euclidean欧几里得相似度计算函数源码如下: public double euclideanSimilarity(@Name("vector1") List<Number> vector1, @Name("vector2") List<Number> vector2) {return 1.0d / (1 + euclideanDistance(vector1, vector2));}
algo.similarity.euclideanDistance欧几里得距离计算函数源码如下: public double euclideanDistance(@Name("vector1") List<Number> vector1, @Name("vector2") List<Number> vector2) {if (vector1.size() != vector2.size() || vector1.size() == 0) {throw new RuntimeException("Vectors must be non-empty and of the same size");}int len = Math.min(vector1.size(), vector2.size());double[] weights1 = new double[len];double[] weights2 = new double[len];for (int i = 0; i < len; i++) {weights1[i] = vector1.get(i).doubleValue();weights2[i] = vector2.get(i).doubleValue();}return Math.sqrt(Intersections.sumSquareDelta(weights1, weights2, len));}Intersections.sumSquareDelta()方法源码如下: public static double sumSquareDelta(double[] vector1, double[] vector2, int len) {double result = 0;for (int i = 0; i < len; i++) {double delta = vector1[i] - vector2[i];result += delta * delta;}return result;}总结:由以上两端代码可知,欧几里得相似度算法函数依赖于欧几里的距离函数,Intersections.sumSquareDelta()欧几里得中对两个vector集合求了方差,euclideanDistance中对方差结果开根方。由此可知欧几里得相似度算法传入得参数值必须长度一致
上一篇:NEO4J-相似度算法03-皮尔逊相似度(Pearson)应用场景简介