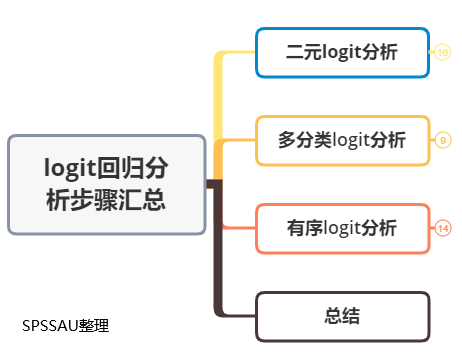
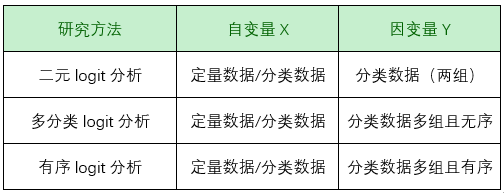
Logit回归分析用于研究X对Y的影响,并且对X的数据类型没有要求,X可以为定类数据(可以做虚拟变量设置),也可以为定量数据,但要求Y必须为定类数据,并且根据Y的选项数,使用相应的数据分析方法。logit回归分析一般可分为三类,分别是二元logit回归、多分类logit回归、有序logit回归,三类logit回归区别如下:
一、二元logit分析
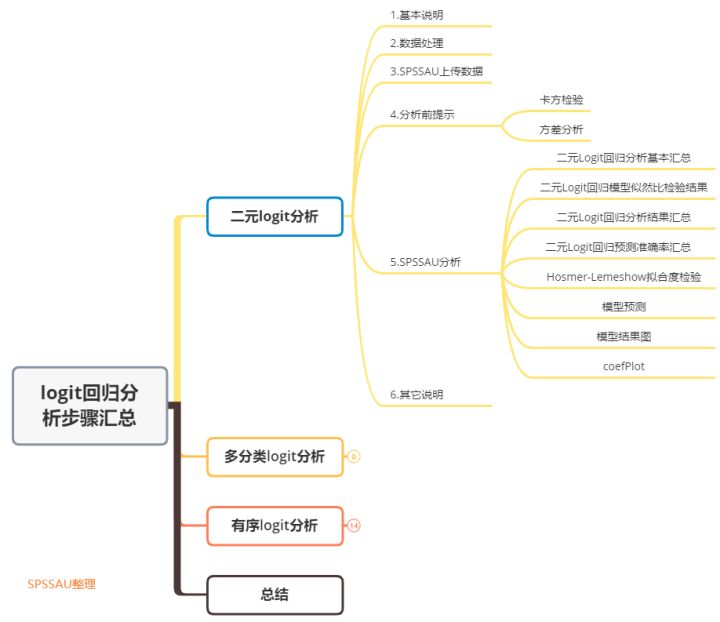
1.基本说明
二元Logit回归分析用于研究X对于Y的影响关系,其中X通常为定量数据(如果X为定类数据,一般需要做虚拟(哑)变量设置)
Y为二分类定类数据,(Y的数字一定只能为0和1)例如愿意和不愿意、是和否等。
2.数据处理
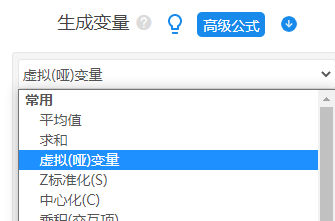
(1)如果X是定类数据,比如性别或学历等。那么就需要首先对它们做虚拟哑变量处理,使用SPSSAU“数据处理”-“生成变量”功能。操作如下图:
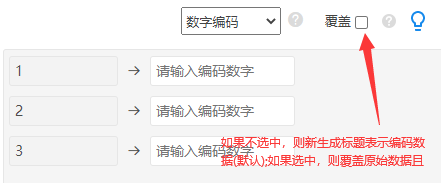
(2)因变量Y只能包括数字0和1,如果因变量的原始数据不是这样,那么就需要数据编码,设置成0和1,使用SPSSAU“数据处理”-“数据编码”功能,操作如下图:
3.SPSSAU上传数据
(1)登录账号后进入SPSSAU页面,点击右上角“上传数据”,将处理好的数据进行“点击上传文件”上传即可。

(2)拖拽分析项
在“进阶方法”模块中选择“二元Logit”方法,将Y定类变量放于上方分析框内,X定类/定量变量放于下方分析框内,点击“开始分析”即可。
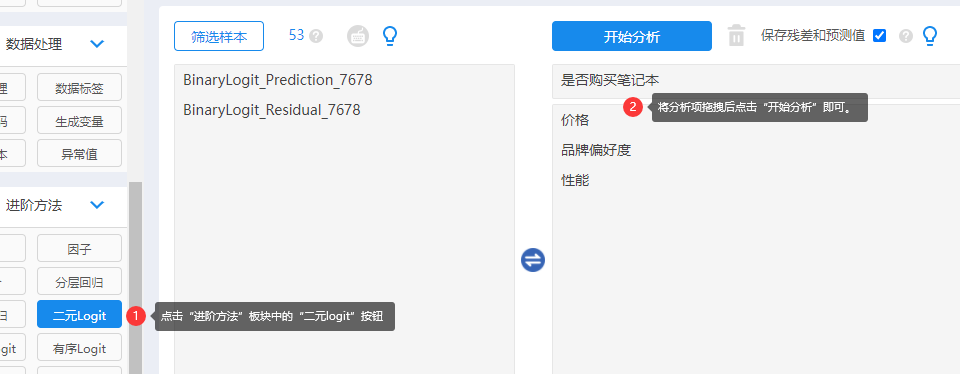
可以勾选“保存残差和预测值” 将残差和预测值保存起来,可用于进—步分析使用。
4.分析前提示
(1)如果X为定类数据,此时可以考虑使用交叉卡方分析去研究X和Y的关系。 (2)如果X非常多(比如超过10个),此时可以先对定类的X与Y进行卡方分析,对定量的X与Y进行方差分析(或t检验),先看有没有差异关系,将最终有差异关系的X放入二元Logit回归模型中,这样X会较少,并且X与Y均有差异关系,也更可能有影响关系,此时二元Logit回归模型的预测准确率会更高。 如果例子里面自变量X较少,模型本身并不复杂,可忽略此步骤即可,直接进行二元logistic回归分析。
5.SPSSAU分析
背景:研究影响用户购买某品牌笔记本电脑的因素,其中0代表否,1代表是(仅供案例分析)。
(1)二元Logit回归分析基本汇总
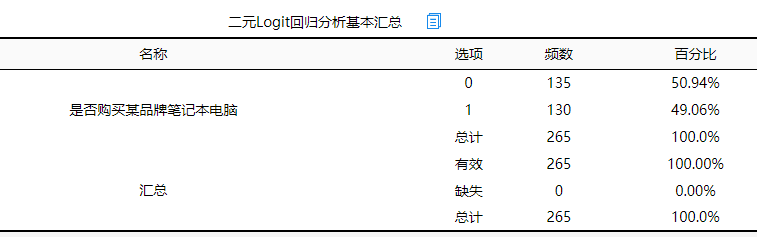
将价格, 品牌偏好度, 性能作为自变量,而将是否购买某品牌笔记本电脑作为因变量进行二元Logit回归分析,从上表可以看出,总共有265个样本参加分析,并且没有缺失数据。

(2)二元Logit回归模型似然比检验结果

分析结果来源于SPSSA

首先对模型整体有效性进行分析,从上表可知:此处模型检验的原定假设为:是否放入自变量(价格, 品牌偏好度, 性能)两种情况时模型质量均一样;这里p值小于0.05,因而说明拒绝原定假设,即说明本次构建模型时,放入的自变量具有有效性,本次模型构建有意义。
(3)二元Logit回归分析结果汇总
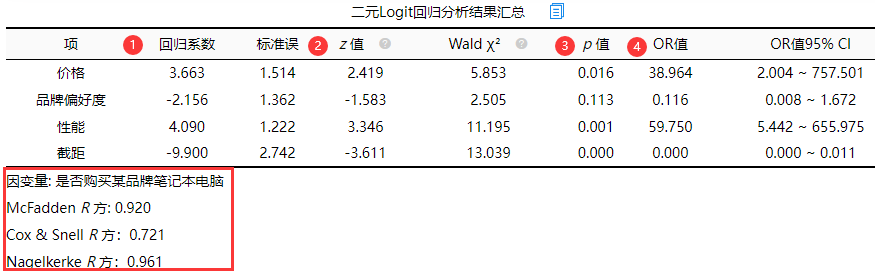
从上表可知,将价格, 品牌偏好度, 性能共3项为自变量,而将是否购买某品牌笔记本电脑作为因变量进行二元Logit回归分析,模型公式为:ln(p/1-p)=-9.900 + 3.663*价格-2.156*品牌偏好度 + 4.090*性能(其中p代表是否购买某品牌笔记本电脑为1 的概率,1-p代表是否购买某品牌笔记本电脑为0的概率)。最终具体分析可知:
价格的回归系数值为3.663,并且呈现出0.05水平的显著性(z=2.419,p=0.016<0.05),意味着价格会对是否购买某品牌笔记本电脑产生显著的正向影响关系。以及优势比(OR值)为38.964,意味着价格增加一个单位时,是否购买某品牌笔记本电脑的变化(增加)幅度为38.964倍。
品牌偏好度的回归系数值为-2.156,但是并没有呈现出显著性(z=-1.583,p=0.113>0.05),意味着品牌偏好度并不会对是否购买某品牌笔记本电脑产生影响关系。
性能的回归系数值为4.090,并且呈现出0.05水平的显著性(z=3.346,p=0.001<0.05),意味着性能会对是否购买某品牌笔记本电脑产生显著的正向影响关系。以及优势比(OR值)为59.750,意味着性能增加一个单位时,是否购买某品牌笔记本电脑的变化(增加)幅度为59.750倍。
总结分析可知:价格, 性能共2项会对是否购买某品牌笔记本电脑产生显著的正向影响关系。但是品牌偏好度并不会对是否购买某品牌笔记本电脑产生影响关系。
此外Logit回归时会提供三个R 方值(分别是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方),此3个R 方均为伪R 方值,其值越大越好,但其无法非常有效的表达模型的拟合程度,意义相对交小,而且多数情况此3个指标值均会特别小,研究人员不用过分关注于此3个指标值。一般报告其中任意一个R方值指标即可。
(4)二元Logit回归预测准确率汇总


通过模型预测准确率去判断模型拟合质量,从上表可知:研究模型的整体预测准确率为96.23%,模型拟合情况良好。当真实值为0时,预测准确率为96.30%;另外当真实值为1时,预测准确率为96.15%。
(5)Hosmer-Lemeshow拟合度检验

Hosmer-Lemeshow拟合度检验用于分析模型拟合优度情况,从上表可知:此处模型检验的原定假设为:模型拟合值和观测值的吻合程度一致;这里p值大于0.05(卡方值为3.109,p=0.927>0.05),因而说明接受原定假设,即说明本次模型通过HL检验,模型拟合优度较好。
(6)模型预测
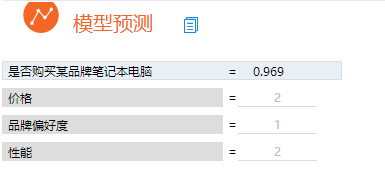
将价格、品牌偏好度以及性能输入该模型就能够预测消费者是否购买某品牌笔记本电脑。
(7)模型结果图
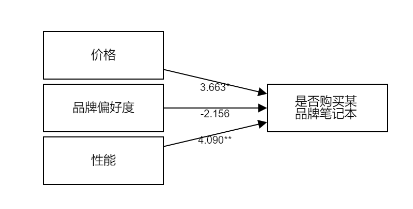
可以更直观的看见自变量与因变量的关系。
(8)coefPlot
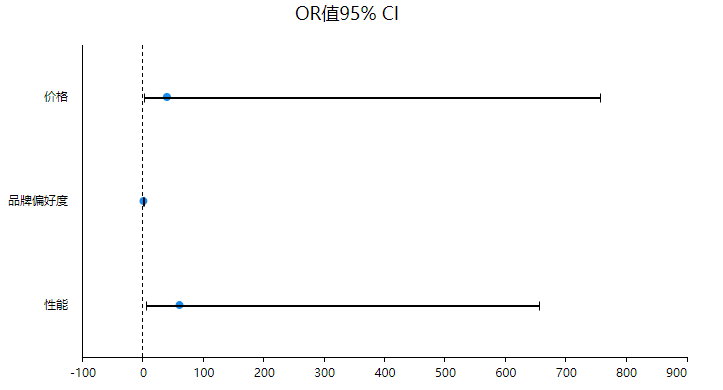
分析结果来源于SPSSAU
coefPlot展示具体的回归系数值和对应的置信区间,可直观查看数据的显著性情况,如果说置信区间包括数字0则说明该项不显著,如果置信区间不包括数字0则说明该项呈现出显著性。
6.其它说明
(1)二元logit回归提示数据质量异常?
如果出现此提示,建议按以下步骤进行检验。
第一:将所有分析项(X和Y全部一起)做相关分析,查看是否有相关系数非常低或 者非常高的项;如果非常低(比如小于0.1)说明完全没有关联关系,非常高(比如 大于0.8)说明共线性问题严重,将此类自变量移除出去,再次分析就好;
第二:检查因变量Y的分布情况,因变量Y仅仅两个数字0和1,如果分布严重不均匀(比如100个样本中仅5个样本为0,95个为1),有可能出现模型无法收敛最后无法输出结果;
第三:自变量中放入虚拟变量,比如学历有5项,虚拟变量出来为5项,5项全部都放入了模型,这一定会出错;
第四:分析样本量过小,比如分析项有10个,但分析样本量仅20个。
(2)Y值只能为0或1?
二元logistic回归研究X对Y的影响,Y为两个类别,比如是否愿意,是否喜欢,是否购买等,数字一定有且仅为2个,分别是0和1。如果不是这样就会出现此类提示,可使用SPSSAU频数分析进行检查,并且使用数据处理-数据编码功能进行处理成0和1。
(3)crude OR和adjusted OR值?
在SPSSAU中进行二元Logit回归,如果放入一个X,得到的OR值即为crude OR,如果放入该X的时候还放入其余的控制项,并且得到对应该X的OR值,就称为adjusted OR值。
二、多分类logit分析
1.基本说明
只要是logit回归,都是研究X对于Y的影响,区别在于因变量Y上,如果Y有多个选项,并且各个选项之间不具有对比意义,例如,1代表“黑龙江省”,2代表“云南省”,3代表“四川省”,4代表“陕西省”,数值仅代表不同类别,数值大小不具有对比意义,那么应该使用多分类Logit回归分析。
2.数据要求与处理
如果说因变量Y的类别个数很多,比如为10个,此时建议时对类别进行组合下,尽量少的减少类别数量,便于后续进行分析。此步骤可通过SPSSAU数据处理模块的数据编码功能完成。
如果说自变量X是定类数据,那么可对X进行虚拟哑变量处理,使用SPSSAU数据处理模块的生成变量功能。关于虚拟(哑)变量问题,请查看:(SPSSAU虚拟(哑)变量帮助手册)。其实定类数据在做影响关系研究时,通常都会做虚拟哑变量处理。
3.SPSSAU上传数据
(1)登录账号后进入SPSSAU页面,点击右上角“上传数据”,将处理好的数据进行“点击上传文件”上传即可。

(2)拖拽分析项
在“进阶方法”模块中选择“多分类Logit”方法,将Y定类变量放于上方分析框内,X定类/定量变量放于下方分析框内,点击“开始分析”即可。
可以勾选“保存预测类别” 将预测值保存起来,可用于进—步分析使用。
4.SPSSAU分析
背景:研究影响手机偏好的因素(仅供案例分析)。
(1)多分类Logistic回归分析基本汇总

将年龄, 学历, 性别作为自变量,而将手机品牌偏好作为因变量进行多分类Logit回归分析,从上表可以看出,总共有1847个样本参加分析。
(2)多分类Logistic回归模型似然比检验

分析结果来源于SPSSAU

分析建议来源于SPSSAU
此处模型检验的原定假设为:是否放入自变量(年龄, 学历, 性别)两种情况时模型质量均一样;这里p值小于0.05,因而说明拒绝原定假设,即说明本次构建模型时,放入的自变量具有有效性,本次模型构建有意义。
(3)多分类Logistic回归分析结果汇总
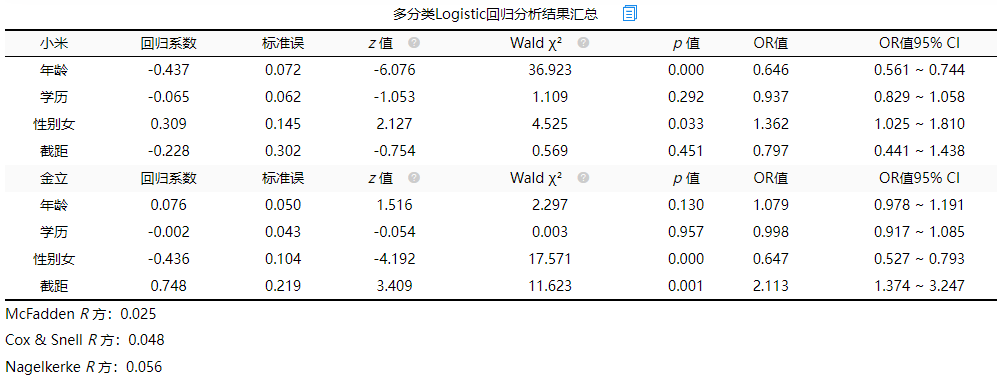
上表格中可以看出年龄和性别的p值<0.05均呈现显著性,以下具体说明:
女性的回归系数值为0.309,并且呈现出0.05水平的显著性(z=2.127,p=0.033<0.05),这说明女性更加偏好于小米手机。原因:在多分类logit回归中,SPSSAU将因变量Y的第1项(此处为华为手机)作为参照项。那么性别女呈现出正向影响,就说明相对于华为手机来讲,女性明显更加偏好于小米手机。
相对华为手机来讲,年龄的回归系数值为-0.437,并且呈现出0.01水平的显著性(z=-6.076,p=0.000<0.01),负向影响,即说明年龄越大用户越偏好于华为手机。
金立手机分析结果可以看出女性相对于更喜欢华为手机,年龄越大用户越偏好于金立手机。

此外Logit回归时会提供三个R 方值(分别是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方),此3个R 方均为伪R 方值,其值越大越好,但其无法非常有效的表达模型的拟合程度,意义相对交小,而且多数情况此3个指标值均会特别小,研究人员不用过分关注于此3个指标值。一般报告其中任意一个R方值指标即可。
(4)预测准确率汇总
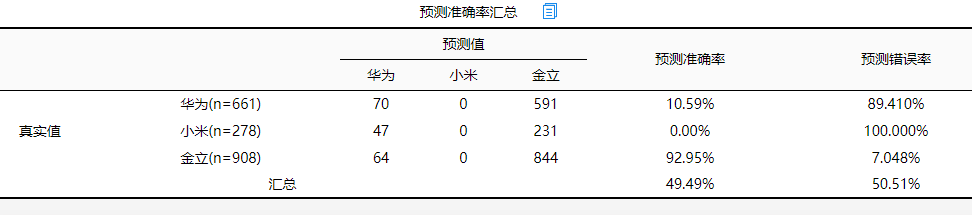
通过模型预测准确率去判断模型拟合质量,从上表可知:研究模型的整体预测准确率为49.49 %,模型拟合情况一般。
5.其它说明
(1)提示“Y的选项过少或过多”?
如果出现此提示,意味着因变量Y的选项不符合多分类logit回归分析要求,通常情况下因变量Y的分类个数应该介于3~8个之间。
1)研究者可使用SPSSAU频数分析功能进行查看因变量Y的选项个数情况;
2)如果选项个数过多需要进行合并处理等,可使用SPSSAU【数据处理->数据编码】功能操作。
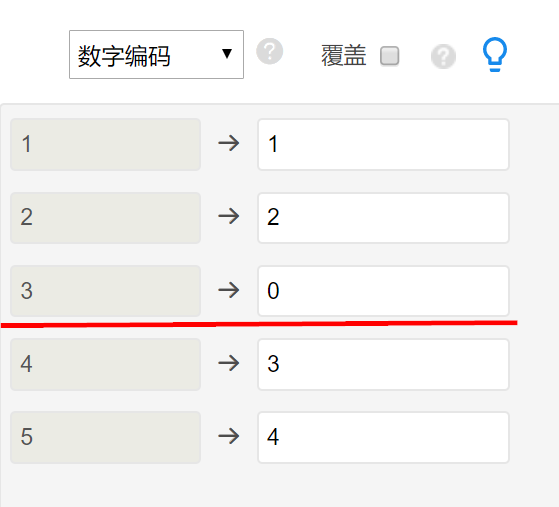
(2)参照项或参考项设置问题?
进行多分类Logit时, SPSSAU默认以第一项【即数字最小的那项】作为参考项。如果需要进行改变,可使用【数据处理->数据编码】功能进行设置,将参考项的数字设为最小即可,如下图所示(原本以1作为参考项,现在改为3作为参考项,将3设置为数字最小0即可,当然设置其它更小值比如-1也可以):
三、有序logit分析
1.基本说明
只要是logit回归,都是研究X对于Y的影响,区别在于因变量Y上,如果Y有多个选项,并且各个选项之间具有对比意义,例如:1代表不满意,2代表一般,3代表满意就可以使用有序logit回归分析。
2.SPSSAU上传数据
(1)登录账号后进入SPSSAU页面,点击右上角“上传数据”,将处理好的数据进行“点击上传文件”上传即可。
(2)拖拽分析项
在“进阶方法”模块中选择“有序Logit”方法,将Y定类变量放于上方分析框内,X定类/定量变量放于下方分析框内,点击“开始分析”即可。
3.参数选择
(1)接连函数选择

(2)平行性检验选择
用于检验各回归方程相互平行。如果不满足平行性检验(或出现异常),建议使用多分类Logit回归即可。
4.SPSSAU分析
背景:究民众幸福度影响因素,包括性别,年龄,学历和年收入水平共4个潜在的影响因素对于幸福水平的影响情况。
(1)有序Logistic回归分析因变量频数分布

本次有序Logit回归模型将性别(女性作为参照项), 年龄, 学历, 年收入水平作为自变量,将幸福水平作为因变量进行有序logistic回归分析,从上表可知:幸福水平共分为三个类别,分布较为均匀,其中比较幸福这一类别的占比较低为20.70%。
(2)有序Logistic回归模型平行性检验

首先对模型进行平行性检验,从上表可知:平行性检验的原假设是各回归方程互相平行,分析显示接受原假设(χ²=1.858,p =0.762> 0.05),因而说明本次模型通过平行性检验,模型分析结论可信,可继续进一步的分析。
如果没有通过平行性检验则有以下建议:
1)改用多分类logit回归;换个方法,因为一般可使用有序logit回归的数据也可以使用多分类logit回归分析;
2)改用线性回归;可考虑换成线性回归分析尝试;
3)改变连接函数;选择更适合的连接函数;
4)将因变量的类别选项进行一些合并处理等,使用SPSSAU数据处理->数据编码功能。
一般来说,有序logit回归有一定的稳健性,即平行性检验对应的p值接近于0.05时,可考虑直接接受有序logit回归分析的结果。
(3)有序Logistic回归模型似然比检验

首先对模型整体有效性进行分析(模型似然比检验),从上表可知:此处模型检验的原定假设为:是否放入自变量(年龄, 年收入水平, 文化程度, 性别男)两种情况时模型质量均一样;分析显示拒绝原假设(chi=62.510,p=0.000<0.05),即说明本次构建模型时,放入的自变量具有有效性,本次模型构建有意义。
补充说明:SPSSAU还提供AIC和BIC这两个指标值,如果模型有多个,而且希望进行模型之间的优劣比较,可使用此两个指标,此两个指标是越小越好。具体可直接查看SPSSAU的智能分析和分析建议即可。
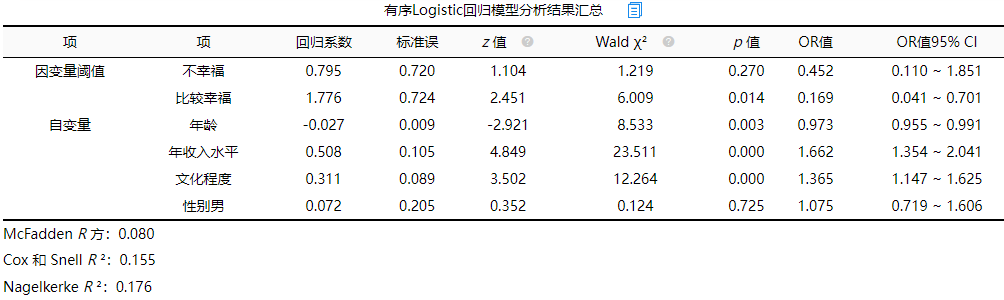
(4)有序Logistic回归模型分析结果汇总
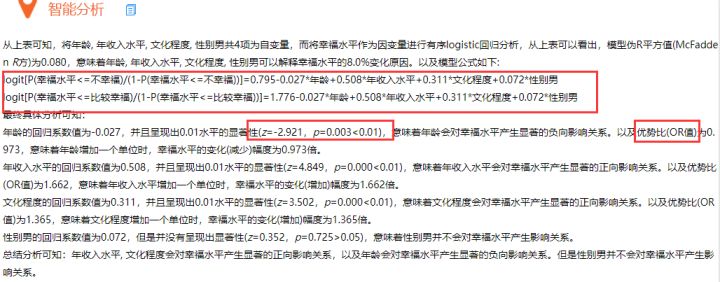
(5)有序Logistic回归模型预测准确率

通过模型预测准确率去判断模型拟合质量,从上表可知:研究模型的整体预测准确率为55.65%,模型拟合情况较差。建议剔除掉无关的自变量,或者对自变量进行数据编码组合重新处理后再次进行分析,得到更佳的分析结果,同时可考虑使用多分类logit回归进行分析。
(6)模型结果图
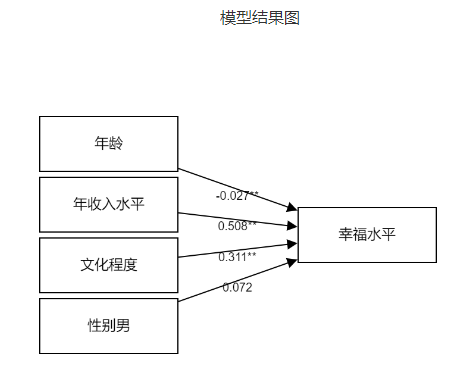
可以更直观的看见自变量与因变量的关系(基于回归系数的基础上)。
(7)coefPlot
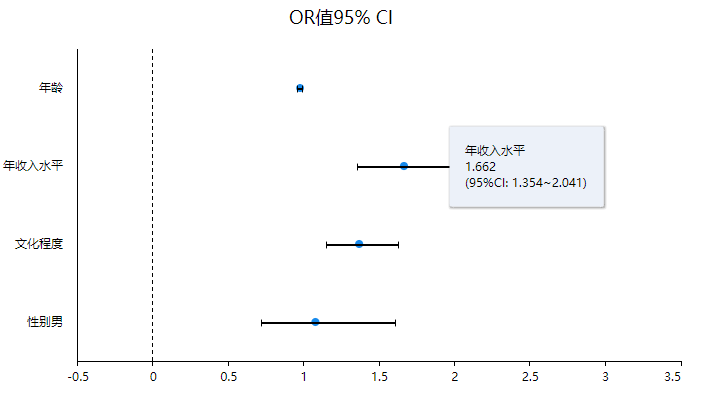
coefPlot展示具体的回归系数值和对应的置信区间,可直观查看数据的显著性情况,如果说置信区间包括数字0则说明该项不显著,如果置信区间不包括数字0则说明该项呈现出显著性。可以看到年龄、年收入水平、文化程度以及性别男的or值以及95%CI。
5.其它说明
(1)OR值的意义
OR值=exp(b)值,即回归系数的指数次方,该值在医学研究里面使用较多,实际意义是X增加1个单位时,Y的增加幅度。如果仅仅是研究影响关系,该值意义较小。
(2)z 值的意义是什么?
z 值=回归系数/标准误,该值为中间过程值无意义,只需要看p 值即可。有的软件会提供wald值(但不提供z 值,该值也无实际意义),wald值= z 值的平方。
四、总结
本篇文章包括二元logit回归步骤分析、多分类logit回归步骤分析、有序logit回归步骤分析,其中二元Logit回归分析时,首先可以分析p 值,如果此值小于0.05,说明具有影响关系,接着再具体研究影响关系情况即可,比如是正向影响还是负向影响关系等;除此之外,还可以写出二元Logit回归分析的模型构建公式,以及模型的预测准确率情况等。
对于多分类Logit回归分析模型的具体情况进行分析,首先分析p 值,如果此值小于0.05,说明X对于Y有影响关系,接着再具体研究影响关系情况即可,比如是正向影响还是负向影响关系等;除此之外,还可以写出回归模型构建公式,以及模型的预测准确率情况等。
有序Logit回归分析时,首先进行模型平行性检验,如果p 值大于0.05,说明满足平行性检验,如果p 值小于0.05,说明不满足平行性检验,此时SPSSAU建议使用多分类Logit回归分析;满足平行性检验后,接着再具体研究影响关系情况即可,比如是正向影响还是负向影响关系等;除此之外,还可以写出有序Logit回归分析的模型构建公式,以及模型的预测准确率情况等。
以上就是本次分享的内容,登录SPSSAU官网了解更多。