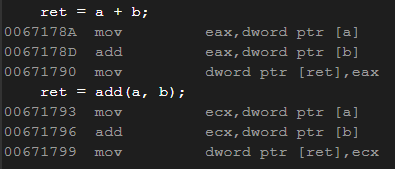
Logit Adjust
BER
我们在分类问题中常用的误分类函数使得分类器最终学到的分布:
P ( y ∣ x ) ∝ P ( y ) P ( x ∣ y ) P(y|x) \propto P(y)P(x|y) P(y∣x)∝P(y)P(x∣y)
假设在一个不平衡猫狗二分类问题中,狗是一个小类,只有整个数据集的1%的数据量。则 P ( y ) = 0.01 P(y)=0.01 P(y)=0.01,这样无论 P ( x ∣ y ) P(x|y) P(x∣y)有多大,右边这一项都会很小。所以作者使用BER即banlance error rate,
首先举一个例子方便快速理解BER的思想:
源地址

根据上面这个混淆矩阵有 B E R = 0.5 ∗ ( b a + b + c c + d ) BER = 0.5 * (\frac{b}{a+b}+\frac{c}{c+d}) BER=0.5∗(a+bb+c+dc)通常的误差计算公式则为 E R = b + c a + b + c + d ER=\frac{b + c}{a+b+c+d} ER=a+b+c+db+c再看原文中给出的BER的公式:
B E R ( f ) = 1 L ∑ y ∈ [ L ] P x ∣ y ( y ∉ a r g m a x y ′ ∈ y ^ f y ′ ( x ) ) BER(f) = \frac{1}{L}\sum_{y \in [L]}P_{x|y} (y \notin argmax_{y^{\prime} \in \hat{y}}f_{y^{\prime}}(x)) BER(f)=L1y∈[L]∑Px∣y(y∈/argmaxy′∈y^fy′(x))
y ^ \hat{y} y^等价于原文中的花体y,有 y ^ = [ L ] = 1 , 2 , … L . \hat{y}=[L]={1, 2, \dots L}. y^=[L]=1,2,…L.上式右边用人话翻译过来就是“把所有(类别) y y y被分类器 f y ′ ( x ) f_{y^\prime}(x) fy′(x)误分类的概率加起来,最后对类别数做平均”。精髓就在于误差的计算是class-wise的,想想我们通常评估误差率,都是用一个batch中,用 误 分 类 样 本 数 b a t c h s i z e \frac{误分类样本数}{batchsize} batchsize误分类样本数来表示,这个时候分类器就可以偷懒,只要把所有样本都预测为大类就可以在误差率这个评价指标上表现良好。一个问题在于,为甚么上式积分符号下面有一个” x ∣ y x|y x∣y”,这个条件函数的假设是怎么回事? 在我的理解中x是样本,再结合最开始举得例子, P ( x ∣ y ) = b a + b P(x|y) = \frac{b}{a+b} P(x∣y)=a+bb左边翻译过来是“已知为类别y,则其为样本x的概率”,右边翻译过来是“类别y的准确率”,这两者要怎么画上等号呢?还请读者不吝赐教。
BER鼓励分类器学到的分布:
P ( y ∣ x ) ∝ 1 L P ( x ∣ y ) P(y|x) \propto \frac{1}{L}P(x|y) P(y∣x)∝L1P(x∣y)
这样分类器分类时就不会再受到不平衡数据集的影响。但是考虑另一个问题,如果狗这个小类中全部都是二哈,只有一个泰迪,那么分类器很可能会学到 P ( 二 哈 ∣ 狗 ) → 1 P(二哈|狗) \to 1 P(二哈∣狗)→1,这相当于一个不平衡子集的问题。
Logit Adjustment
最小化BER可以表述为 f ∗ ∈ a r g m i n f : x → R L B E R ( f ) f^* \in argmin_{f:x \to R^{L}}BER(f) f∗∈argminf:x→RLBER(f),原文提到这个问题的一个典型的解是:“the best posible or Bayes-optimal score as following:”
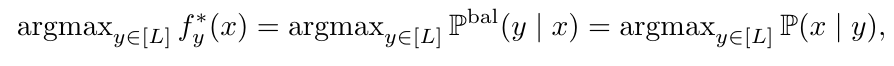
上式右边的等式与上一节中分析BER鼓励分类器学习的分布的形式是一致的。文章中进一步阐述,当类别条件概率 P ( x ∣ y ) P(x|y) P(x∣y)固定的时候,无论 P ( y ) P(y) P(y)怎么变,模型都是无视的,这就直观的解释了,为什么BER可以用于解决类别不平衡的问题。
接着作者假设 P ( y ∣ x ) ∝ e x p ( s y ∗ ( x ) ) P(y|x) \propto exp(s^*_y(x)) P(y∣x)∝exp(sy∗(x)),其中 s ∗ : x → R L s^*:x \to R^L s∗:x→RL是一个记分器(scorer),用来把样 本x映射为一个长度为L向量,向量中的每个元素表示分类器认为该样本属于某一类的分数。使用指数函数一是因为它本身是 R n R^n Rn上单调增的二是因为在外面套上对数函数之后可以把它消掉。同时根据定义有 P b a l ( y ∣ x ) ∝ P ( y ∣ x ) / p ( y ) P^{bal}(y|x) \propto P(y|x)/p(y) Pbal(y∣x)∝P(y∣x)/p(y)。因此上面的长等式又可以表示为:
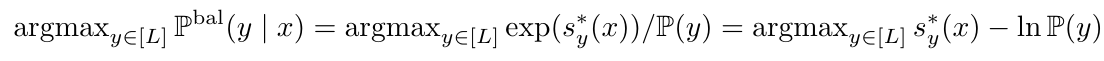 上式最后一项就是作者所谓的logit adjust。作者提出可以有两种形式来执行,其一是整合在loss函数中,其二是在测试的时候做后处理。第一种方式定义的损失函数如下:
上式最后一项就是作者所谓的logit adjust。作者提出可以有两种形式来执行,其一是整合在loss函数中,其二是在测试的时候做后处理。第一种方式定义的损失函数如下:
def build_loss_fn(use_la_loss:bool, base_probs, tau=1.0):def loss_fn(logits, labels):if use_la_loss:logits = logits + torch.log(torch.tensor(base_probs**tau + 1e-12,dtype=torch.float32,device="cuda",).detach())loss = F.cross_entropy(logits, labels)return lossreturn loss_fntau默认是1,也就是不起任何作用,作者给的推荐配置中也没有对这个参数进行修改。加1e-12应该是为了数值稳定性。
最后作者认为自己的方法相对于之前的方法的优势之一是有坚实的统计学基础:最小化平衡误差时保证了费雪一致性(Fisher consistent)。关于这个性质我的浅薄理解就是在一个采样上{X}求得的函数 f : X → θ f:{X} \to \theta f:X→θ,对于真实分布仍然适用。用人话来说就是,我这个函数可以根据这个采样求得这个分布的一个未知参数 θ \theta θ,把这个函数放到真实分布上仍然是正确的,这样我求的这个函数就可以以偏概全。