目录
(一)案例简介
案例使用
数据预处理
分析结果
完整代码
目录 关联分析
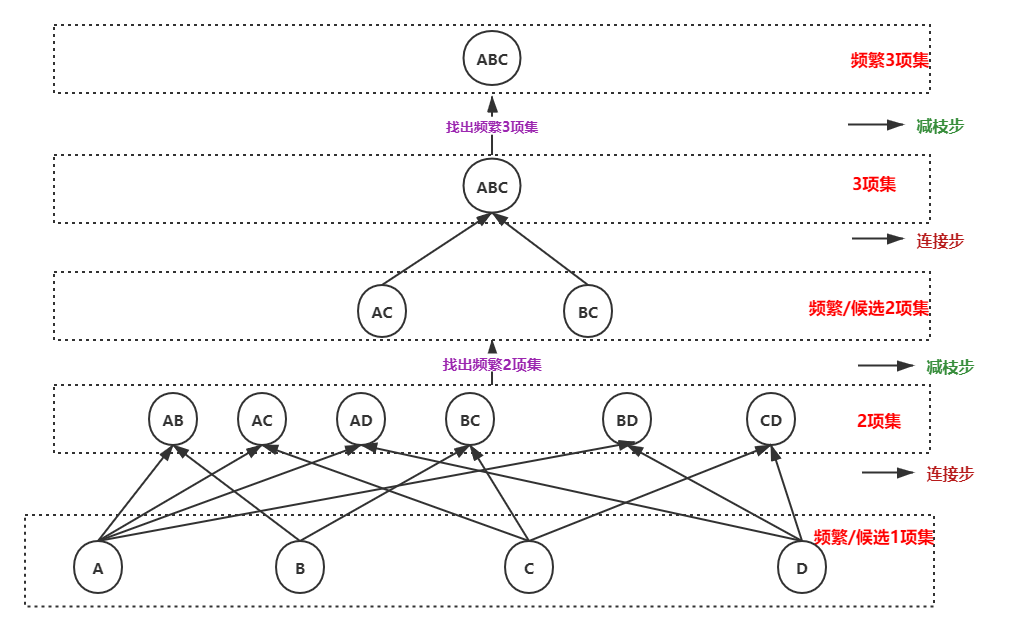
理解关联分析的相关概念:关联分析、支持度、置信度、强规则、项集、频繁项集等。 掌握关联分析的基本方法:数据是事务的或关系的,如何由大量的数据中发现关联规则 ?什么样的关联规则最有趣?
案例资料
(一)案例简介
只有对商场销售数据进行分析,才能了解客户的购买特性,发现不同类别商品的共同特征及其规则,并进而通过这些规则对商场的市场定位、商品定价、新商品采购等进行决策。 本案例采用某大型超市的购物篮数据集,每一组数据表示不同的顾客一次在商场购买的商品 集合。案例的样本数据如表 1.1 所示。
表 1.1 某大型超市的购物篮样本数据

案例使用
读入数据
安装和加载聚类挖掘算法相关的包:arules,用于关联规则的数字化生成,提供 Apriori 和 Eclat
这两种快速挖掘频繁项集和关联规则算法的实现函数。
>install.packages("arules")>library(arules)>library(Matrx) >shopping.df<-as.data.frame(read.csv(file="D:/GLFX/WH.csv",header=F))#读取数据>shopping.df
数据预处理
将原始数据集转换成数据项集。
每个商品用唯一的一个代码表示如下:
I1:面包
I2:鸡蛋
I3:西红柿
I4:茄子
I5:皮带
I6:手表
所有的商品可以表示为数据项集
I: I={I1, I2, I3, I4, I5, I6}
每一条交易记录可以表示为一个数据项集:
T1={I1, I2, I3} T2={I1, I4} T3={I4, I5} T4={I1, I4}
T5={I1, I2, I3, I4, I6} T6={I2, I3, I6}
T7={I2, I3, I6}
#则所有数据项集的集合 D={T1,T2,T3,T4,T5,T6,T7}>Trade1 <- c("In1","In2","In3")>Trade2 <- c("In1","In4")>Trade3 <- c("In4","In5")>Trade4 <- c("In1","In4")>Trade5 <- c("In1","In2","In3","In4","In6")>Trade6 <- c("In2","In3","In6")>Trade7 <- c("In2","In3","In6")>D <- list(Trade1,Trade2,Trade3,Trade4,Trade5,Trade6,Trade7)>D
>shopping.t<- as(D, "transactions")>shopping.t
>inspect(shopping.t)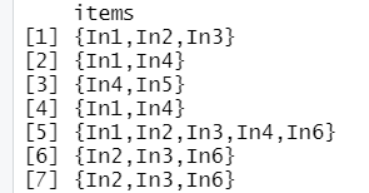
设定支持度和可信度阈值,选择关联规则挖掘算法产生关联规则
apriori()函数的基本格式:apriori(data, parameter = NULL, appearance = NULL, control = NULL)
当放置相应的数据集,并设置各个参数值(如:支持度和置信度的阈值)后,运行该函数即可生成满足需求的频繁项集或关联规则等结果。 Parameter 参数可以对支持度(support)、置信度(confidence)、每个项集所含项数的最大值/最小值(maxlen/minlen),以及输出结果(target)等重要参数进行设置。如果没有对其进行设值,函数将对各参数取默认值:support=0.1,confidence=0.8,maxlen=10,minlen=1,target=“rules”/“frequent itemsets”(输出关联规则/频繁项集)。
而参数 appearance 可以对先决条件 X(lhs)和关联结果 Y(rhs)中具体包含哪些项进行限制出现。如:设置 lhs=beer,将仅输出 lhs 中含有“啤酒”这一项的关联规则,在默认情况下,所有项都将无限制出现。 Control 参数用来控制函数性能,如可以设定对项集进行升序(sort=1) 还是降序( sort=-1)排序,是否向使用者报告进程(verbose=TURE/FALSE) (1)通过支持度、置信度控制 将支持度的最小阈值(minsup)设置为 0.001,置信度最小阈值(mincon) 设为 0.5,其他参数不进行设定取默认值,并将所得关联规则名记为 ShoppingRules0
>ShoppingRules0<-apriori(shopping.t,parameter=list(support=0.001,confidence=0.5)) #生成关联规则
以上输出结果包括指明支持度、置信度最小值的参数详解(parameter specification)部分,记录算法执行过程中相关参数的算法控制(algorithmic control)部分,以及 apriori 算法的基本信息和执行细节,如 apriori 函数的版本、各步骤的程序运行时间等。
>ShoppingRules0 #显示 ShoppingRules0 中生成关联规则条数
>inspect(ShoppingRules0) #观测 ShoppingRules0 中的规则
可以看到 ShoppingRules0 中共包含 62 条关联规则。观察每条观测,关联规则的先后顺序与可以表明其关联性强度的三个参数值的取值大小没有明显关系。
主要通过支持度控制
>ShoppingRules.sorted_sup <- sort(ShoppingRules0, by="support")
#给定置信度阈值为 0.01,按支持度 排序>
>inspect(ShoppingRules.sorted_sup[1:10])
如上输出结果,10 条强关联规则按照支持度从高到低的顺序排列出来。这种控制规则强度的方式可以找出支持度最高的若干条规则。当我们对某一指标要求苛刻时,可以优先考虑该方式, 易于控制输出规则的条数。
主要通过置信度控制
以下类似,按照置信度选出前 10 条强关联规则,由输出结果得到了 10 条置信度高达 100%的关联规则,比如第一条规则:购买靴子,都购买了茄子。这就是一条相当有用的关联规则,正如这些物品在超市中往往摆放的很近
>ShoppingRules.sorted_con <- sort(ShoppingRules0, by="confidence")>inspect(ShoppingRules.sorted_con[1:10])
主要通过提升度控制
>ShoppingRules.sorted_lift <- sort(ShoppingRules0, by="lift")#给定支持度阈值为 0.01,置信度阈值为 0.5, 按提升度排序
>inspect(ShoppingRules.sorted_lift[1:10])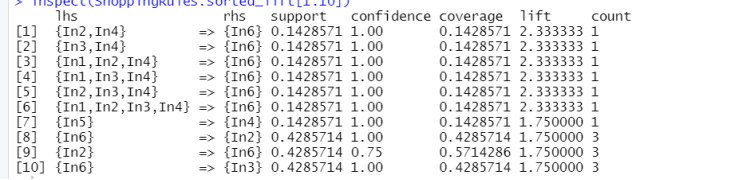
提升度可以说是筛选关联规则最可靠的指标,且得到的结论往往也是有趣有用的。由以上输出 结果可以看到强度最高的关联规则为{鸡蛋,茄子}→{手表},{西红柿,茄子}→{手表}等。
分析结果
销量最高的产品
>itemsets_sho<-apriori(shopping.t,parameter= >list(supp=0.1,target="frequent itemsets"),control = list(sort=-1))#将 apriori()中目标参数取值设为“频繁项集”
inspect(itemsets_sho[1:5])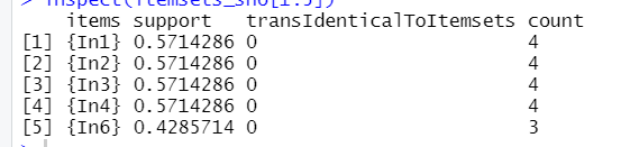
适合捆绑销售的产品
Eclat 算法的核心函数为 eclat()来获取最适合捆绑销售,其格式为: eclat(data, parameter = NULL, control = NULL)与 apriori()相比,参数 parameter 和 control 被保留,其作用与 apriori()中基本相同,但要注意,parammeter 中的输出结果(target)一项不可设置为 rules,即通过 eclat()函数无法生成关联规则,并且 maxlen 的默认值为 5。
>itemsets_esho<-eclat(shopping.t,parameter=list(minlen=2,maxlen=3,supp=0.1,target="frequent itemsets"),control = list(sort=-1))
>inspect(itemsets_esho)
完整代码
install.packages("arules")
library(arules)
library(Matrix)
shopping.df<-as.data.frame(read.csv(file="D:/GLFX/WH.csv",header=F))
shopping.df
Trade1 <- c("In1","In2","In3")
Trade2 <- c("In1","In4")
Trade3 <- c("In4","In5")
Trade4 <- c("In1","In4")
Trade5 <- c("In1","In2","In3","In4","In6")
Trade6 <- c("In2","In3","In6")
Trade7 <- c("In2","In3","In6")
D <- list(Trade1,Trade2,Trade3,Trade4,Trade5,Trade6,Trade7)
D
shopping.t<- as(D, "transactions")
shopping.t
inspect(shopping.t)
ShoppingRules0 <- apriori(shopping.t,parameter = list(support=0.001,confidence=0.5)) #生成关联规则
ShoppingRules0 #显示 ShoppingRules0 中生成关联规则条数
inspect(ShoppingRules0) #观测 ShoppingRules0 中的规则
ShoppingRules.sorted_sup <- sort(ShoppingRules0, by="support")#给定置信度阈值为 0.01,按支持度 排序>
inspect(ShoppingRules.sorted_sup[1:10])
ShoppingRules.sorted_con <- sort(ShoppingRules0, by="confidence")
inspect(ShoppingRules.sorted_con[1:10])
ShoppingRules.sorted_lift <- sort(ShoppingRules0, by="lift") #给定支持度阈值为 0.01,置信度阈值为 0.5, 按提升度排序
inspect(ShoppingRules.sorted_lift[1:10])
itemsets_sho <- apriori(shopping.t, parameter = list(supp=0.1,target="frequent itemsets"),control = list(sort=-1)) #将 apriori()中目标参数取值设为“频繁项集”
inspect(itemsets_sho[1:5])
itemsets_esho <- eclat(shopping.t, parameter = list(minlen=2,maxlen=3,supp=0.1,target="frequent itemsets"),control = list(sort=-1))
inspect(itemsets_esho)