目录
一、Django/ORM框架介绍及配置
1.1、ORM框架介绍
1.2、Django数据库配置
二、定义模型类数
2.1、定义模型类
2.2、迁移
2.3、插入数据
三、单表据库操作(增、删、改、查)
3.1、增
3.2、删
3.3、改
3.4查(重点)
四、两表联查
4.1、一对多、多对一
4.2、一对一
4.3、多对多
五、模型类序列化器
5.1、序列化器介绍
5.2、序列化器使用
5.3、数据的拼接
5.4、自定义序列化器实现添加修改
5.5、模型类序列化器
一、Django/ORM框架介绍及配置
1.1、ORM框架介绍
ORM框架 O是object,也就类对象的意思,R是relation,翻译成中文是关系,也就是关系数据库中数据表的意思,M是mapping,是映射的意思。在ORM框架中,它帮我们把类和数据表进行了一个映射,可以让我们通过类和类对象就能操作它所对应的表格中的数据。ORM框架还有一个功能,它可以根据我们设计的类自动帮我们生成数据库中的表格,省去了我们自己建表的过程。
django中内嵌了ORM框架,不需要直接面向数据库编程,而是定义模型类,通过模型类和对象完成数据表的增删改查操作。
使用django进行数据库开发的步骤如下:
-
配置数据库连接信息
-
在models.py中定义模型类、迁移、插入数据
-
通过类和对象完成数据增删改查操作
1.2、Django数据库配置
项目创建
# 创建项目
django-admin startproject 项目名
# 创建应用app(两条都可实现)
django-admin startapp 应用名
python manage.py startapp 应用名数据库连接(django 默认连接 aqlite3 数据库,这里使用 mysql 数据库)
# 使用mysql数据库需要在主目录的同名子目录下的 __init__.py 文件下配置
import pymysql
pymysql.install_as_MySQLdb() 
# 在主目录的同名子目录下的 settings.py 文件中修改 django 默认数据库
# django 默认连接 sqlite3 数据库
DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3','NAME': os.path.join(BASE_DIR, 'db.sqlite3'),}
}#更改为连接 mysql 数据库
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql', # 指明连接数据库的引擎'NAME': 'django05', # 库名, django 连接的 mysql 数据库库名'HOST': 'localhost', # 数据库的ip地址,'PORT': 3306, # 数据库的端口号'USER': 'root', # 用户名'PASSWORD': 'admin123' # 密码}
}创建数据库
# 在终端登录 mysql
mysql -u root -p
# 输入密码
******
# 创建数据库
create database 库名 charset utf8;若需跨域配置
# 在主目录的同名子目录下的 settings.py 文件中配置INSTALLED_APPS = ["corsheaders"
]MIDDLEWARE = ['django.middleware.security.SecurityMiddleware','django.contrib.sessions.middleware.SessionMiddleware','django.middleware.common.CommonMiddleware',# 'django.middleware.csrf.CsrfViewMiddleware','django.contrib.auth.middleware.AuthenticationMiddleware','django.contrib.messages.middleware.MessageMiddleware','django.middleware.clickjacking.XFrameOptionsMiddleware',"corsheaders.middleware.CorsMiddleware"
]#允许所有源访问
CORS_ORIGIN_ALLOW_ALL =True路由配置
#主路由里添加子路由(需在子应用中创建python file文件的子路由)
from django.urls import path,include
# from app名 import 子路由urlpatterns = [path('admin/', admin.site.urls),# path("路由/",include(“子路由”))# 也可以不导包,直接添加path("路由/",include("app名.子路由"))
]# 子路由中配置
from django.urls import path
# 导入视图
from . import views
urlpatterns = [path("路由/",views.方法名.as_view())
]二、定义模型类数
2.1、定义模型类
模型类需定义在子应用的 models.py 中
常用字段类型
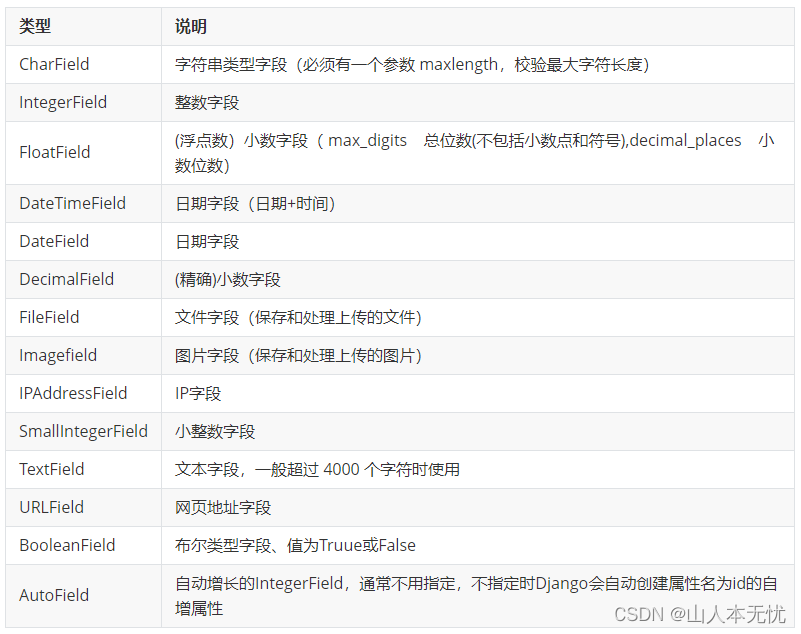
常用字段字段属性
模型类创建案例
不同的数据库中 对应的 sql语句不一样, django为了简单, 统一采用 模型类,模型类 定义在 app/models.py 文件中
from django.db import modelsclass Books(models.Model):# 模型类中不需要指定 id字段,会自动生成name = models.CharField(max_length=20,verbose_name="书名")# 数据库的可变字符串类型 varchar(20)# max_length : 指定可变字符串的最大长度price = models.DecimalField(max_digits=7, decimal_places=2, verbose_name='价格')# 数据库的 金钱有关的字段 decimal(7,2)# max_digits: 指定数字的最大位数,包括小数# decimal_places: 指定小数的 位数hire_date = models.DateField(verbose_name='出版日期')# 数据库的 日期字段 date# auto_now_add: 在对象添加时,自动设置为 当前时间, 后期不再改变# auto_now: 在对象每次更新时,时间都会设置为更新时的时间# 避免矛盾,`auto_now`,`auto_now_add`,`default`不能同时出现,一个字段属性只能有其中一条设置,# 当设置了`auto_now`,或`auto_now_add`时,也会让该字段默认具有`blank=True`(字段可以为空)属性author = models.CharField(max_length=20, verbose_name='作者')num = models.IntegerField(verbose_name='库存', default=0)publish = models.CharField(max_length=20, verbose_name='出版社')type = models.CharField(max_length=10,verbose_name="类别")sales_volume = models.IntegerField(verbose_name='销量', default=0)def __str__(self):# 修改对象的描述信息, 此时查看图书对象,已经不是默认的对象地址信息, 而是图书对象的书名return self.name# 元选项一定属于模型类中的一部分,不能单独使用class Meta:db_table = 'tb_book' # 指定表名, 默认为 app名_模型类名verbose_name = '图书' # amdin中显示的表的名字,为单数形式verbose_name_plural = verbose_name # 复数形式2.2、迁移
模型类创建好后,将模型类迁移到数据库
在终端执行迁移命令,会在对应app下生成一个迁移文件migrations 用来记录数据库迁移的信息
如果数据库出错,需删库重创时,必须把migrations 文件删掉再重新创建,否则报错
# 生成迁移文件
python manage.py makemigrations# 执行迁移文件同步数据到数据库
python manage.py migrate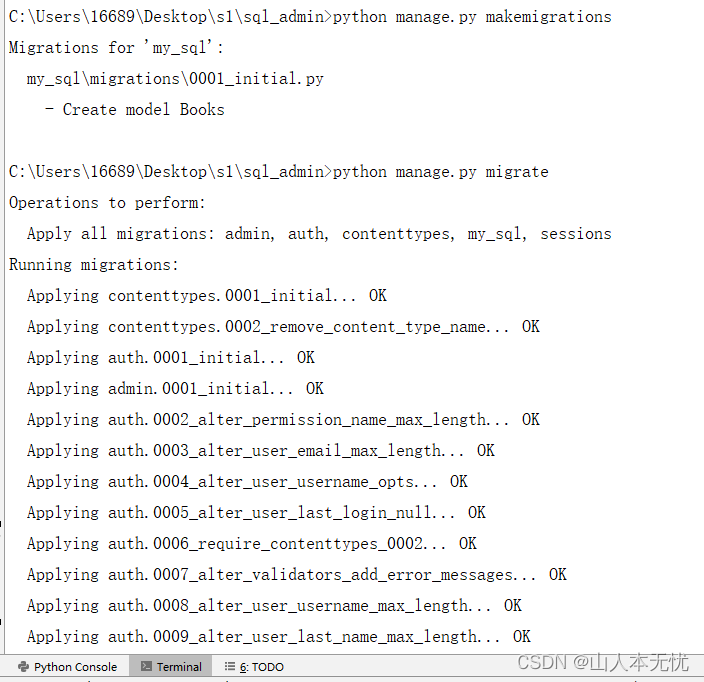
迁移成功生成表格

修改字段、迁移
# 若数据库中未添加数据,修改字段属性,重新执行迁移命令即可
# 若有数据,添加新的字段,新字段的属性为:可以为空 或 有默认值,则可重新执行迁移命令
# 若有数据,想添加一个非空、没有默认值的字段则报:You are trying to add a non-nullable field 'type' to books without a default; we can't do that (the database needs som
ething to populate existing rows).
Please select a fix:1) Provide a one-off default now (will be set on all existing rows with a null value for this column)2) Quit, and let me add a default in models.py翻译:
请选择修复方案: 1)现在提供一个一次性的默认值(将在所有现有行上设置此列的空值) 2)退出,让我在models.py中添加一个默认值 # 选 1 后,需再输入一个默认值,(测试时,输入中文报错,如数据不多,建议再输入默认值: 1 后,在数据库中修改为需要数据),继续执行迁移命令5# 选 2 ,给字段添加default 属性,即可重新迁移
反向迁移
若有一个完整的数据库和数据,想要生成模型类以使用,则可以使用反向迁移,
反向迁移会将所有的表都生成模型类存放在一个文件中,
(只进行过简单尝试了解,并未深入写下去,感受:多个模型类在一起有些杂乱,有些字段属性可能用不到,但确实比自己重新写入模型类迁移插入数据快的多,并且字段对应不会出错,表关系清晰,可以把需要的模型类拉入自己的app下修修改改使用)
django的orm模型已经内置了反向迁移命令
python manage.py inspectdb > models.py # >后面是生成的文件路径和名称
python manage.py inspectdb > ./APP名称/models.py # 生成到指定的app下2.3、插入数据
常用的插入数据方法:一、创建超级用户 二、python连接数据库直接添加
一、创建超级用户
在应用app下的admin.py 下注册
from django.contrib import admin
from .models import *
admin.site.register(模型类名)python manage.py createsuperuser 创建超级用户
邮箱不需要添,账号密码依次设置
初次访问连接:127.0.0.1/admin
访问页面、并操作
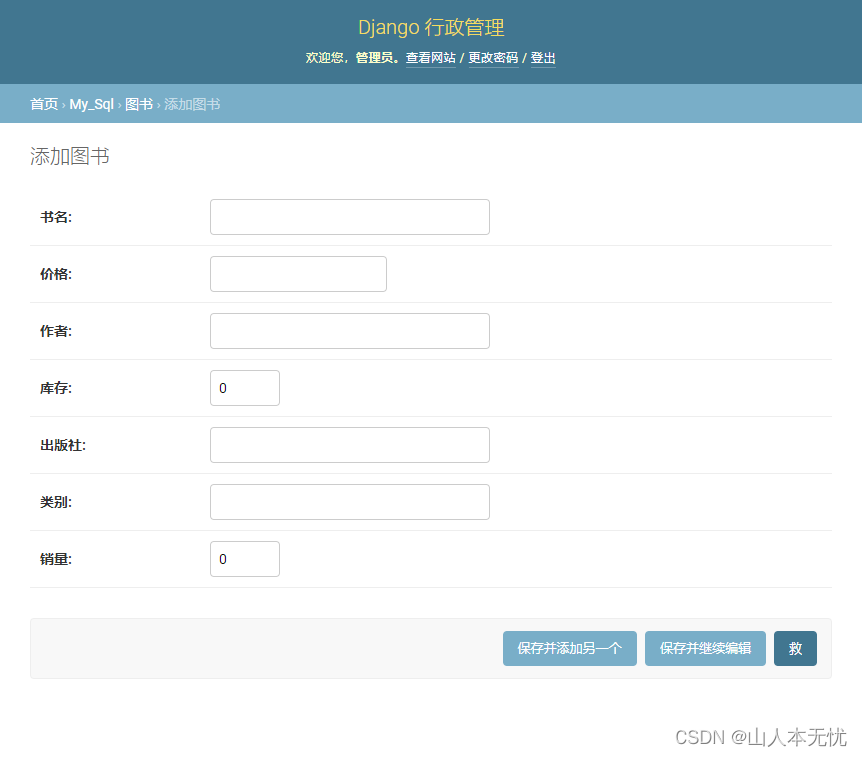
二、python 链接数据库,直接添加
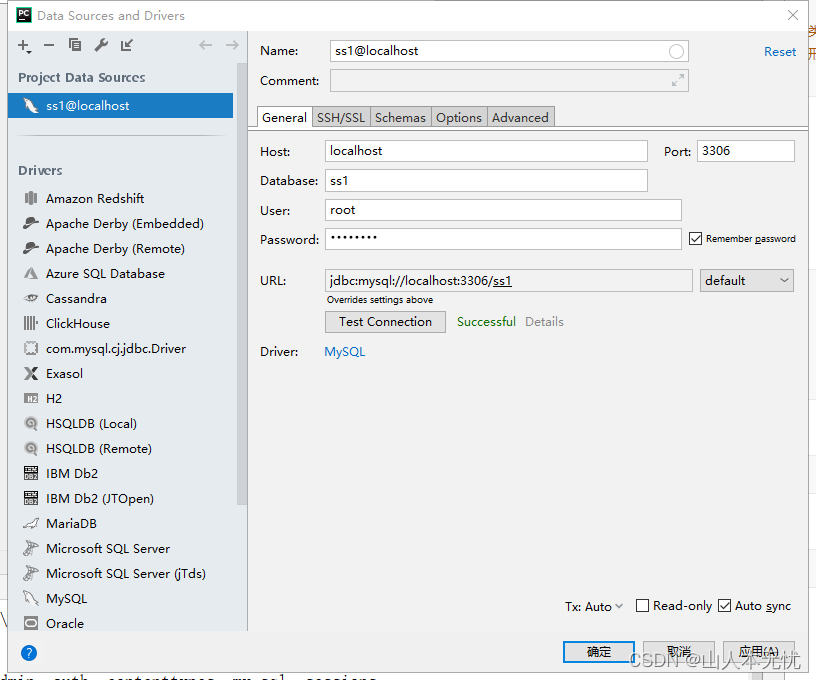
从右侧的database >>>> 点击"+" >>>> Data Source >>>>MYSQL
填写里面的数据,Test Connection验证如果成功就可以往里面添加数据

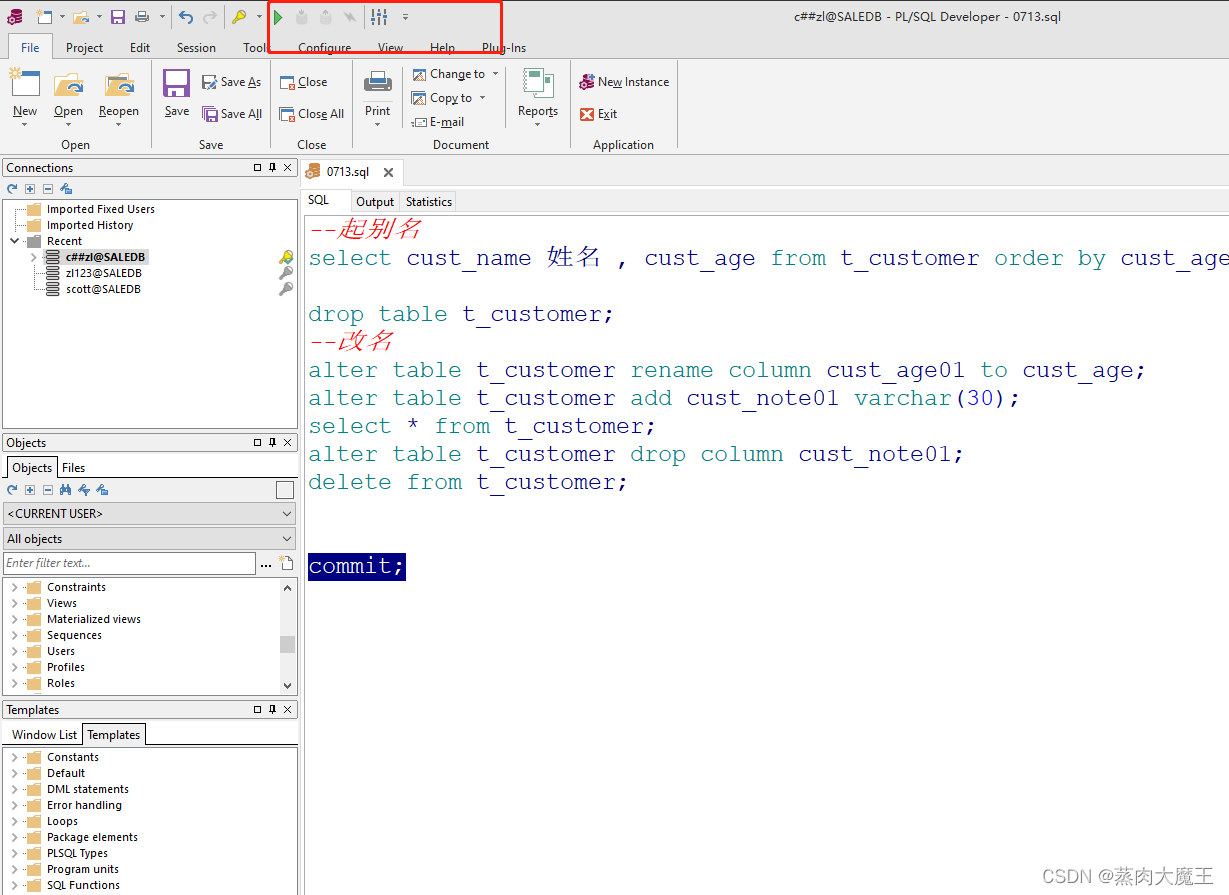
三、单表据库操作(增、删、改、查)
3.1、增
save() :通过创建模型类对象,执行对象的save()方法保存到数据库中。
from datetime import datebook = Books(name= "《剑来》",price = 33,hire_date = date(2020.11.2),author = "烽火戏诸侯",num = 22,publish = "起点",type = "玄幻",sales_volume = 2)book.save()create :通过模型类.objects.create()保存
from datetime import date
Books.objects.create(name= "《雪中悍刀行》",price = 33,hire_date = date(2020.11.2),author = "烽火戏诸侯",num = 22,publish = "顶点",type = "玄幻",sales_volume = 2)3.2、删
通过get/filter 获取到需要删除的数据,使用delete()方法直接删除
book = Books.objects.get(id = 7)
book.delete()book = Books.objects.filter(name= "《雪中悍刀行》")
book.delete()Books.objects.get(id = 8).delete()Books.objects.filter(name= "《雪中悍刀行》").delete()逻辑删除
逻辑删除只是给表添加字段,用来记录数据的状态,删除也只是修改了数据状态,查询的时候把这些数据筛选出去,看上去是删除了
例:添加字段 status 默认值为1,表示存在,当要删除时,把status 改为0,表示删除。查询数据的时候,加一个判断条件status = 1,这样获取的数据就是理论上还存在的,这种方法称为逻辑删除
3.3、改
save :修改模型类对象的属性,然后执行save()方法(单条数据修改)
book = Books.objects.get(id = 6)
book.publish = "笔趣阁"
book.save()update
使用模型类.objects.filter().update(),(多条数据修改)
Books.objects.filter(num=22).update(publish="番茄阅读")3.4查(重点)
查询所有
# 查询所有数据
>>> Books.objects.all()
<QuerySet [<Books: 《斗破苍穹》>, <Books: 《斗罗大陆》>, <Books: 《遮天》>,<Books: 《坏蛋是怎样炼成的》>, <Books: 《曹贼》>, <Books: 《剑来》>, <Books: 《雪中
悍刀行》>]>
获取查询的数据 values
# 查询id=1的详细数据(values不能使用get,会报错)
>>> Books.objects.filter(id=1).values()
<QuerySet [{'id': 1, 'name': '《斗破苍穹》', 'price': Decimal('25.00'), 'hire_date': datetime.date(2022, 5, 3), 'author': '天蚕土豆', 'num': 100, 'publish': '笔趣阁', 'type': '玄幻', 'sales_volume': 500}]># 查询的数据为查询集,想取里面的数据需要切片取值
# 查询所有数据,获取斗破苍穹数据里的id
>>> book = Books.objects.all()
>>> print(">>>>>>>>",book)
>>> print(">>>>>>>>",book[0])
>>> print(">>>>>>>>",book[0].id)
>>>>>>>> <QuerySet [<Books: 《斗破苍穹》>, <Books: 《斗罗大陆》>, <Books: 《遮天》>,<Books: 《坏蛋是怎样炼成的》>, <Books: 《曹贼》>, <Books: 《剑来》>, <Books: 《雪中悍刀行》>]>
>>>>>>>> 《斗破苍穹》
>>>>>>>> 1
查询单个
# 查询id = 2 的数据
>>> Books.objects.get(id = 2)
《斗罗大陆》# 如果查询不存在或者有多个,则会抛出异常,这时可以使用filter 过滤查询
# 查询id= 30的数据,表中不存在id = 30 数据
>>> Books.objects.get(id = 30)
Traceback (most recent call last):File "D:\jiaocai\soft\python\python\lib\site-packages\django\core\handlers\excepti
on.py", line 34, in innerresponse = get_response(request)
......File "D:\jiaocai\soft\python\python\lib\site-packages\django\db\models\query.py",
line 408, in getself.model._meta.object_name
my_sql.models.Books.DoesNotExist: Books matching query does not exist.# 查询num= 22 的数据,表中num = 22 数据有两条
>>> Books.objects.get(num=22)
Traceback (most recent call last):File "D:\jiaocai\soft\python\python\lib\site-packages\django\core\handlers\excepti
on.py", line 34, in inner
......
my_sql.models.Books.MultipleObjectsReturned: get() returned more than one Books -- it returned 2!
查询数量
# 查询Books 表中的数据的数量
>>> Books.objects.count()
7filter 过滤查询
# 查询num= 22 的数据
>>> Books.objects.filter(num=22)
<QuerySet [<Books: 《剑来》>, <Books: 《雪中悍刀行》>]>
# 查询id=30的数据,id= 30 没有数据,
>>> Books.objects.filter(id = 30)
<QuerySet []>模糊查询 (字段名__contains)判断是否包含,如果要包含%无需转义,直接写即可。
运算符都区分大小写,在这些运算符前加上i表示不区分大小写、icontains
# 查询书名包含“斗”的书籍
>>> Books.objects.filter(name__contains="斗")
<QuerySet [<Books: 《斗破苍穹》>, <Books: 《斗罗大陆》>]>
startswith、endswith :以指定值开头或结尾
运算符都区分大小写,在这些运算符前加上i表示不区分大小写、istartswith、iendswith
# 查询以“剑”开头的数据,因数据加书名号,所以查询也要加
>>> Books.objects.filter(name__startswith="《剑")
<QuerySet [<Books: 《剑来》>]>
空查询 isnull 是否为空 Flase/True
# 查询名字不为空的,
>>> Books.objects.filter(name__isnull=False)
<QuerySet [<Books: 《斗破苍穹》>, <Books: 《斗罗大陆》>, <Books: 《遮天》>,<Books: 《坏蛋是怎样炼成的》>, <Books: 《曹贼》>, <Books: 《剑来》>, <Books: 《雪中
悍刀行》>]>
in、range范围查询
# 查询id在1,2,3,4里的数据
>>> Books.objects.filter(id__in=[1,2,3,4])
<QuerySet [<Books: 《斗破苍穹》>, <Books: 《斗罗大陆》>, <Books: 《遮天》>,<Books: 《坏蛋是怎样炼成的》>]># 查询id在1-4内的数据
>>> Books.objects.filter(id__range=(1,3))比较查询
gt :大于 (greater then)
gte:大于等于 (greater then equal)
lt :小于 (less then)
lte :小于等于 (less then equal)
# 查询id大于等于3的数据
>>> Books.objects.filter(id__gte=3)
<QuerySet [<Books: 《遮天》>, <Books: 《坏蛋是怎样炼成的》>, <Books: 《曹贼》>, <Books: 《剑来》>, <Books: 《雪中悍刀行》>]>
日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
# 查询出版日期在2021年的数据
>>> Books.objects.filter(hire_date__year=2021)
<QuerySet [<Books: 《雪中悍刀行》>]># 查询出版日期在2022年7月1日之前的数据
>>> Books.objects.filter(hire_date__lte=date(2022,7,1))
<QuerySet [<Books: 《斗破苍穹》>, <Books: 《坏蛋是怎样炼成的》>, <Books: 《雪中悍刀行》>]>F 查询 同一条数据的两个字段做比较
# 库存大于销量的数据
# F 方法使用时注意导包
>>> from django.db.models import F
>>> Books.objects.filter(num__gt=F("sales_volume"))
<QuerySet [<Books: 《斗罗大陆》>, <Books: 《曹贼》>, <Books: 《剑来》>]>
Q 查询
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
& 表示逻辑与、and,| 表示逻辑或、or
# 查询id 大于3,库存大于200的数据
# Q 方法使用时注意导包
>>> Books.objects.filter(id__gt=3,num__gt=200)
>>> Books.objects.filter(id__gt=3).filter(num__gt=200)
>>> Books.objects.filter(Q(id__gt=3) & Q(num__gt=200))
<QuerySet [<Books: 《曹贼》>]>
Q对象前可以使用~操作符,表示非not 、
# 查询id 不等于3的数据
>>> Books.objects.filter(~Q(id=3))
.exclude(条件): 查询出和条件相反的结果集
# 查询id 不等于3的数据
>>> Books.objects.exclude(id=3)
聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg(平均),Count(数量),Max(最大),Min(最小),Sum(求和),被定义在django.db.models中,需导包,返回值 {'属性名__聚合类小写':值}
# 查询库存总数 (Avg/Max/Min/Sum 等用法一致)
>>> from django.db.models import Sum,Avg,Max,Min
>>> Books.objects.aggregate(Sum("num"))
>>> Books.objects.all().aggregate(Sum("num"))
{'num__sum': 869}# 查询所有信息的数量
>>> Books.objects.all().count()
7排序 order_by
# 查询所有数据按库存排序(根据字段排序为升序,字段前加负号 “-” 为降序
>>> Books.objects.all().order_by("num") # 升序
>>> Books.objects.all().order_by("-num") # 降序四、两表联查
常用两表关系
一对多:ForeignKey
一对一:OneToOneField
多对多:ManyToManyField
4.1、一对多、多对一
4.1.1、创建(老师为一,学生为多)
# 老师
class Teacher(models.Model):name = models.CharField(max_length=10, verbose_name='姓名')gender = models.IntegerField(choices=((0,"男"),(1,"女")),verbose_name='性别')# 学生
class Student(models.Model):name = models.CharField(max_length=10, verbose_name='姓名')score = models.IntegerField(verbose_name='成绩')# 此时的teacher 和 数据库中的 外键字段不太一样, 他是关联的整个老师对象, 并不是老师的id# 但是通过模型类生成的表中的 字段就是 老师的id# 也可以设置外键可以为空null=True,这样写入学生数据时可以不用提供老师的信息,如果外键设置不为空时,保存会引发错误teacher = models.ForeignKey(to=Teacher, on_delete=models.CASCADE, verbose_name='老师')# to:关联的模型类# on_delete: 此时学生关联老师,如果要删除老师, 对应的学生应该怎么办# CASCADE: 删除老师,与之关联的学生也会被删除在创建一对多的关系的,需要在ForeignKey的第二参数中加入on_delete=models.CASCADE 主外关系键中,级联删除,也就是当删除主表的数据的时候从表中的数据也随着一起删除。
这是数据库外键定义的一个可选项,用来设置当主键表中的被参考列的数据发生变化时,外键表中响应字段的变换规则的。
update 是主键表中被参考字段的值更新;delete是指在主键表中删除一条记录
on_update 和 on_delete 后面可以跟的词语有四个:
1. no action 表示 不做任何操作,
2. set null 表示在外键表中将相应字段设置为null
3. set default 表示设置为默认值
4. cascade 表示级联操作,就是说,如果主键表中被参考字段更新,外键表中也更新,主键表中的记录被删除,外键表中改行也相应删除
4.1.2、增
# 增加老师,和单表一样
teacher = Teacher.objects.create(name='李老师', gender=1)# 增加学生, 学生中的外键teacher实际是一个老师对象
# 通过外键_id形式给外键赋值 id
stu = Student.objects.create(name="小明",score=98,teacher_id=1)# 直接给外键赋值一个老师对象 (注:必须是对象,get查询获取的是对象,filter查询获取的是查询集,需切片才可使用)
teacher = Teacher.objects.filter(id=2)
stu = Student.objects.create(name="小明",score=98,teacher=teacher[0]) 4.1.3、删
# 删除学生(正常删除)
Student.objects.get(id = 9).delete()# 删除老师(因创建表的时候,两表定义的关系为:on_delete=models.CASCADE ,所以删除老师,其对应的学生也会被删除)
Teacher.objects.filter(id=4).delete()4.1.4、改
# 修改老师
Teacher.objects.filter(id=3).update(name="李老师")# 修改学生(修改需要用 filter 获取学生的查询集,使用 get 报错)
Student.objects.filter(id = 6).update(teacher_id = 1)4.1.5、查
# 正向查询:通过学生,查询对应老师
# 查询id为1的学生,以及对应的老师
# 1. 查询学生对象
student = Student.objects.get(id=1)# 2. 想要获取对应的老师信息 (对象.外键.关联模型类的字段)
teacher = student.teacher.name# 反向查询:通过老师,查询老师的学生
# 查询id为1 的老师 以及他对应的学生
# 1. 查询老师对象
teacher = Teacher.objects.get(id=1)# 2. # 通过django内置的 属性 模型类_set, 可以反向查询老师名下的所有学生
student = teacher.student_set.all()
4.2、一对一
4.2.1、创建
# 一个老师对应一个班级,切记:外键一对一不能重复
# 班级:名字、地址
class Cls(models.Model):name = models.CharField(max_length=10, verbose_name='班级名称')address = models.CharField(max_length=20, verbose_name='教室地址')# 老师
class Teacher(models.Model):name = models.CharField(max_length=10, verbose_name='姓名')gender = models.IntegerField(choices=((0,"男"),(1,"女")),verbose_name='性别')cls = models.OneToOneField(to=Cls, on_delete=models.CASCADE)4.2.2、增
# 添加班级
Cls.objects.create(name='四年级', address='304')# 添加老师(由于老师和班级是一对一的关系,一个老师只能对应一个班级,所以添加班级表的外键一定不能和之前的重复,否则报错)
Teacher.objects.create(name="宋老师",gender=1,cls_id=4)4.2.3、删
# 删除班级,其对应的老师也会被删除
Cls.objects.get(id=3).delete()# 删除老师,其班级不变化
Teacher.objects.get(id=4).delete()4.2.4、改
# 修改老师
Teacher.objects.filter(id=2).update(cls_id=4)# 修改班级
Cls.objects.filter(id=4).update(name="三年级")4.2.5、查
# 正向查询,通过老师,查询对应班级
teacher = Teacher.objects.get(id=1)
cls1 = teacher.cls.name# 反向查询,通过班级查询老师, 反向查询时,只需要 模型类 本身即可
cls1 = Cls.objects.get(id=1)
teacher = cls1.teacher.name4.3、多对多
4.3.1、创建
# 类别:名字
class Type(models.Model):name = models.CharField(max_length=10,verbose_name="类别名")# 书籍(之前的单表,将其 类别 设置为外键,实现多对多的关系,一本书可以有多个类别,一个类别可以对应多本书)
class Books(models.Model):name = models.CharField(max_length=20,verbose_name="书名")price = models.DecimalField(max_digits=7, decimal_places=2, verbose_name='价格')hire_date = models.DateField(verbose_name='出版日期')author = models.CharField(max_length=20, verbose_name='作者')num = models.IntegerField(verbose_name='库存', default=0)publish = models.CharField(max_length=50, verbose_name='出版社')# type = models.CharField(max_length=10,verbose_name="类别")sales_volume = models.IntegerField(verbose_name='销量', default=0)# 多对多没有 on_delete参数type = models.ManyToManyField(to=Type)# 在多对多的情况,有专门的第三张表,存储 对应关系,表本身并没有字段来存储对应关系,此时删除任意数据,不影响另一张表数据
4.3.2、增
# 添加类别
Type.objects.create(name="黑道")# 添加书籍
book = Books.objects.create(name= "《雪中悍刀行》",price = 33,hire_date = date(2021,1,2),author = "烽火戏诸侯",num = 22,publish = "顶点",sales_volume = 2)# 给书籍添加类别
# 对象.关联字段.add(关联的type表的id)
book.type.add(1,2,3)
4.3.3、删
# 多对多关联字段的删除,要使用 remove 来进行关系的断开,而不是直接使用 delete ,remove 只会断开数据之间的联系,但是不会将数据删除
# 解除书籍绑定的标签
type1 = Type.objects.get(id=1)
book = Books.objects.get(id=1)
# 书籍对象.关联字段.remove(类别对象)
book.type.remove(type1)4.3.4、改
# 先解除关联,在重新添加新关联4.3.5、查
# 正向查询 :通过书籍查询对应的类别
book = Books.objects.get(id=1)
# 通过外键查询该书籍的全部类别
type1 = book.type.all()# 反向查询:通过类别查询该类别的书籍
type1 = Type.objects.get(id=1)
# 查询该类别对应的所有书籍
book = type1.books_set.all()五、模型类序列化器
5.1、序列化器介绍
序列化组件的作用
前后端通常是通过json格式进行数据传递,但是json序列化不能序列化对象,而序列化组件,可以自定义特定结构把对象序列化返回给前端,同时可以对前端传入的参数进行数据校验等功能
QuerySet如何进行Json处理
book_set = Book.objects.all()books = []
for book in book_set:books.append({'id': book.id,'btitle': book.btitle,'price': book.price,'bread': book.bread,'bcomment': book.bcomment})序列化是将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据
序列化:从Django数据库 >>>>> Django的模型 >>>>> JSON/XML等文本格式
例如:我们在django的ORM中获取到的数据默认是模型对象,但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给别人。
反序列化:上面过程的反方向
例如:前端js提供过来的json数据,对于python而言就是字符串,我们需要进行反序列化换成模型类对象,这样我们才能把数据保存到数据库中。
模型类序列化器与序列化器的区别
ModelSerializer与常规的Serializer相同,但提供了:
基于Django模型类自动生成一系列字段
基于Django模型类自动为序列化器生成validators
包含默认的create() 创建方法和update() 更新方法的实现
DRF 框架(使用DRF框架里的序列化方法)
这个框架提供了如下功能,让我们的代码风格更加统一,而且让你的开发工作成本更低,这个框架封装了很多很多复用的功能
- 将请求的数据转换为模型类对象
- 操作数据库
- 将模型类对象转换为响应的数据如 JSON 格式
- 视图封装:DRF统一封装了请求的数据为request.data以及返回数据的Response方法
- 序列化器:DRF提供了序列化器可以统一便捷的进行序列化及反序列化工作
- 认证:对用户登陆进行身份验证
- 权限:对用户权限进行认证,超级用户、普通用户、匿名用户啥的
- 限流:对访问的用户流量进行限制,减轻接口的访问压力
- 过滤:可以对列表数据进行字段过滤,并可以通过添加django-fitlter扩展来增强支持
- 排序:来帮助我们快速指明数据按照指定字段进行排序
- 分页:可以对数据集进行分页处理
- 异常处理:DRF提供了异常处理,我们可以自定义异常处理函数
- 接口文档生成:DRF还可以自动生成接口文档
5.2、序列化器使用
安装DRF框架
pip install djangorestframework -i https://pypi.tuna.tsinghua.edu.cn/simple配置 settings
INSTALLED_APPS = [...'rest_framework',
]models.py 创建模型类
from django.db import modelsclass Books(models.Model):name = models.CharField(max_length=20,verbose_name="书名")price = models.DecimalField(max_digits=7, decimal_places=2, verbose_name='价格')hire_date = models.DateField(verbose_name='出版日期')author = models.CharField(max_length=20, verbose_name='作者')num = models.IntegerField(verbose_name='库存', default=0)publish = models.CharField(max_length=50, verbose_name='出版社')sales_volume = models.IntegerField(verbose_name='销量', default=0)在应用下创建文件 serializers.py 定义序列化
from rest_framework import serializers# 1. 定义序列化类, 依赖于模型类
# 2. 指定序列化器字段, 字段和模型类的字段一样
# max_length: 校验name存储的字符串的 最大长度
# min_length: 校验name存储的字符串的 最小长度
# 序列化器中的字符串长度,可以不写,只有在反序列化时,才会使用
class BookSer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField(max_length=20,label="书名")price = serializers.DecimalField(max_digits=7, decimal_places=2, label='价格')hire_date = serializers.DateField(label='出版日期')author = serializers.CharField(max_length=20, label='作者')num = serializers.IntegerField(label='库存', default=0)publish = serializers.CharField(max_length=50, label='出版社')sales_volume = serializers.IntegerField(label='销量', default=0)
在 views.py 里使用
from .serializers import BookSer
from django.http import JsonResponse
from rest_framework.views import APIViewclass Getbook(APIView):def post(self,request):# 若使用get获取对象,序列化器里不需要加 many=True# 若使用filter、all 获取查询集,序列化里需要加 many=True# JsonResponse默认只允许转换 字典格式, 当需要转换非字典时,需要 设置safe参数为 Falsebook = Books.objects.filter(id=1)ser = BookSer(book,many=True)return JsonResponse(ser.data,safe=False)
返回的数据
[{"id": 1,"name": "《斗破苍穹》","price": "25.00","hire_date": "2022-05-03","author": "天蚕土豆","num": 100,"publish": "笔趣阁","sales_volume": 500}
]5.3、数据的拼接
models.py 创建模型类(一对多关系)
# 老师
class Teacher(models.Model):name = models.CharField(max_length=10, verbose_name='姓名')gender = models.IntegerField(choices=((0,"男"),(1,"女")),verbose_name='性别')# 学生
class Student(models.Model):name = models.CharField(max_length=10, verbose_name='姓名')score = models.IntegerField(verbose_name='成绩')teacher = models.ForeignKey(to=Teacher, on_delete=models.CASCADE, verbose_name='老师')
一对多时,定义普通的序列化数据展示
class StuSer(serializers.Serializer):id = serializers.IntegerField(read_only=True)# read_only=True,指明当前字段只参与序列化(查询), 不参与反序列化(添加)name = serializers.CharField()score = serializers.IntegerField()teacher_id = serializers.IntegerField()class Getstu(APIView):def post(self,request):stus = Student.objects.all()ser = StuSer(stus,many=True)return Response(ser.data)展示数据
[{"id": 1,"name": "张三","score": 85,"teacher_id": 1},{"id": 2,"name": "李四","score": 88,"teacher_id": 1}
]一对多时,定义普通的序列化数据展示不太全面,这时可以直接拼接数据
from django.http import JsonResponse
from rest_framework.views import APIView
from rest_framework.response import Responseclass Addstu(APIView):def post(self,request):stus = Student.objects.all()stu_list = []for stu in stus:stu_list.append({"id":stu.id,"name":stu.name,"score":stu.score,# 方便的获取学生对应的老师信息"teacher":stu.teacher.name,"teacher_gender":stu.teacher.gender})# 使用Response 返回效果一样# return Response(stu_list)return JsonResponse(stu_list,safe=False)返回数据
[{"id": 1,"name": "张三","score": 85,"teacher": "张老师","teacher_gender": 0},{"id": 2,"name": "李四","score": 88,"teacher": "张老师","teacher_gender": 0}
]5.4、自定义序列化器实现添加修改
定义序列化器
from rest_framework import serializers
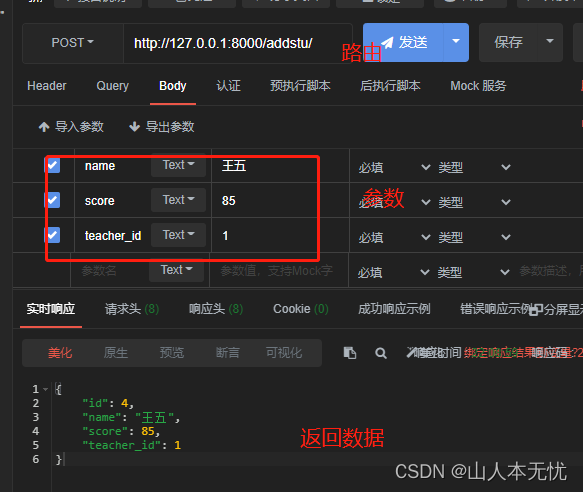
from .models import Studentclass StuSer(serializers.Serializer):id = serializers.IntegerField(read_only=True)# read_only=True,指明当前字段只参与序列化(查询), 不参与反序列化(添加)name = serializers.CharField()score = serializers.IntegerField()teacher_id = serializers.IntegerField()# 1.1 需要利用序列化器实现数据的反序列化添加,# 需要自定义实现 create 方法,def create(self, data):# data是一个形参,格式是字典,存储就是需要添加的数据, 如 {"name":"王五, "score": 37, "teacher_id":1}# 1.1.1 在方法中利用模型类创建对象stu = Student.objects.create(**data) # ** 就是将字典进行拆包,按照键值对的形式传入create方法# 1.1.2 返回创建后的对象return stu# 1.2 如果需要利用序列化器实现数据的更新,需要自定义实现update方法def update(self, instance, validated_data):""":param instance: 需要更新的实例对象, 这个序列化器对应学生, 所以 instance代表学生对象:param validated_data: 需要更新的新数据:return: 返回更新后的新对象"""# 1.2.1 从字典中按照键取值,如果不存在,设置默认值,# 然后将取到的值 赋值给学生对象的属性instance.name = validated_data.get('name', instance.name)instance.score = validated_data.get('score', instance.score)instance.teacher_id = validated_data.get('teacher_id', instance.teacher_id)instance.save() # 1.2.2属性更新之后,需要重新保存# 1.2.3 返回更新后的新对象return instance添加、views.py视图
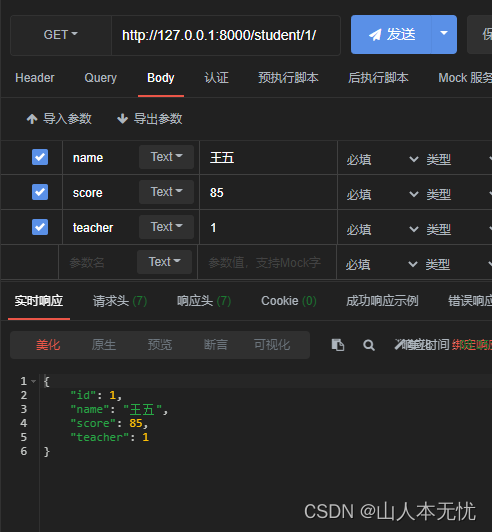
class Addstu(APIView):def post(self,request):# 1.2.1 获取参数data = request.data# 1.2.2 创建序列化器对象ser = StuSer(data=data)# 1.2.3 调用序列化器对象的验证方法进行验证, 如果有误,直接返回错误信息ser.is_valid(raise_exception=True)# 1.2.4 保存数据ser.save()# 1.2.5 返回创建后的对象信息,需要指明状态码return Response(ser.data, status=201)
修改、views.py 视图
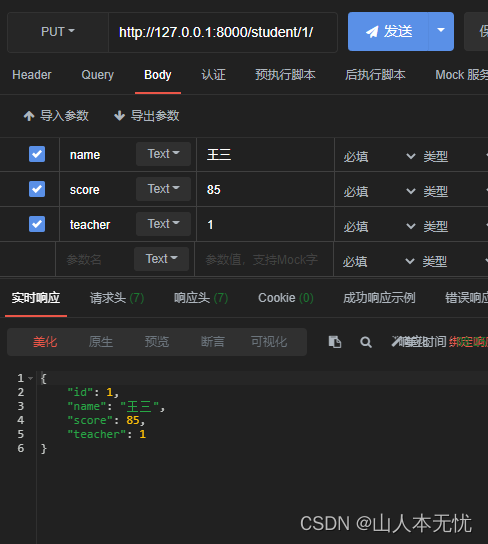
class Putstu(APIView):# 修改对象属性,需要id,def put(self, request, pk):# 1. 查询到id对应的对象, 当id不存在时,找不到对象,会抛出异常try:stu = Student.objects.get(id=pk)except Exception as e:return Response({'msg': 'NOT FOUND'}, status=404)# 2. 获取新数据data = request.data# 3. 创建序列化器对象ser = StuSer(stu, data=data)# 4. 校验ser.is_valid(raise_exception=True)# 5. 保存ser.save()# 6. 返回更新后的新对象, 更细或创建成功,状态码都是201return Response(ser.data, status=201)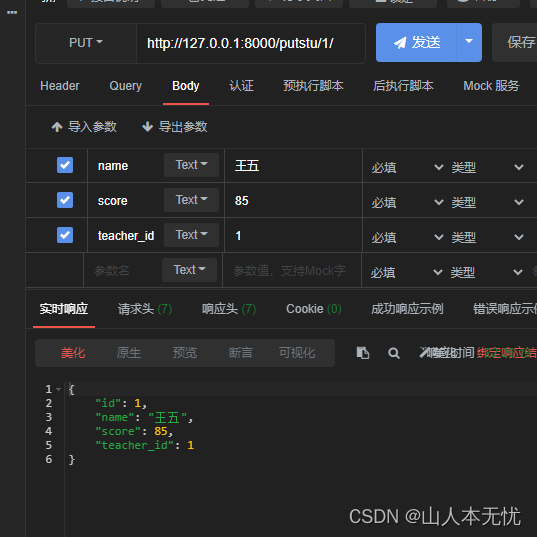
5.5、模型类序列化器
定义模型类序列化器
from rest_framework import serializers
from .models import Studentclass Stuser(serializers.ModelSerializer):# 必须定义元类class Meta:# 指明需要序列化的模型类model = Student# 指明模型类的所有字段参与序列化与反序列化# 不需要所有字段时可自己定义,例:["id","name","score"]fields = "__all__"# 深度、查看关联对象而不是一个id,depth应该是整数,表明嵌套的层级数量(一般不用)# depth = 1视图获取全部、添加
from rest_framework.views import APIView
from rest_framework.response import Response
from .serializers import StuSerclass StudentView(APIView):def get(self,request):# 1. 查询全部数据,得到查询集students = Student.objects.all()# 2. 创建序列化器对象, 同时需要设置参数many=Trueser = StuSer(students, many=True)# 3. 返回序列化数据return Response(ser.data)def post(self, request):# 1. 获取客户端发送的数据data = request.data# 2. 创建序列化器对象ser = StuSer(data=data)# 3. 验证,如果错误,直接返回错误信息ser.is_valid(raise_exception=True)# 4. 保存ser.save()# 5. 返回序列化数据return Response(ser.data, status=201)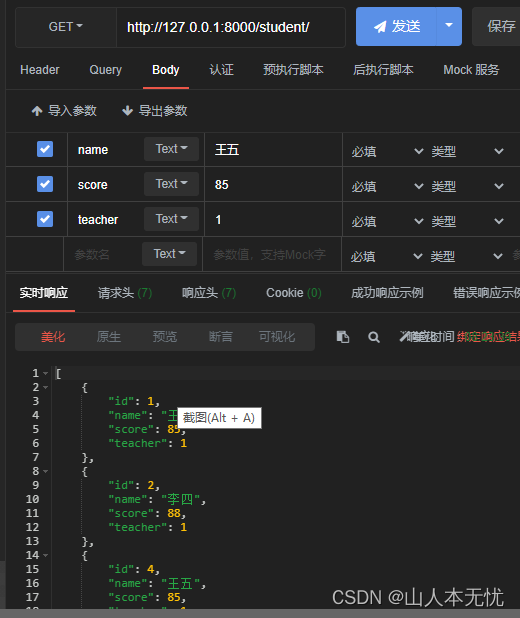
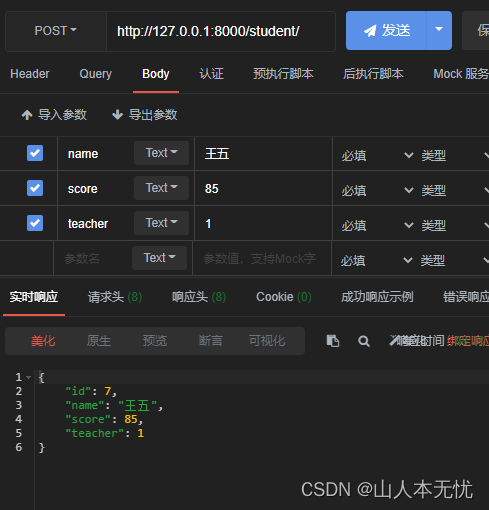
视图、查询单个、删除、修改
# 查询单个、删除、修改
class StudentDetailView(APIView):def get(self, request, pk):# 1. 查询id对应的数据,得到对象try:student = Student.objects.get(id=pk)except Exception as e:return Response({'msg': 'NOT FOUND'}, status=404)# 2. 创建序列化器对象ser = StuSer(student)# 3. 返回序列化数据return Response(ser.data)def put(self, request, pk):# 1. 查询特定对象try:student = Student.objects.get(id=pk)except Exception as e:return Response({'msg': 'NOT FOUND'}, status=404)# 2. 获取参数data = request.data# 3. 创建序列化器对象ser = StuSer(student, data=data)# 4. 验证ser.is_valid(raise_exception=True)# 5. 保存ser.save()# 6. 返回序列化后的数据return Response(ser.data)def delete(self, request, pk):# 1. 利用id直接找到数据,并删除Student.objects.filter(id=pk).delete()# 2. 返回状态码 `204`return Response(status=204)
路由配置
path('student/', StudentView.as_view()), # 增、查全部
path('student/<int:pk>/', StudentDetailView.as_view()), # 查单个、修改、删除