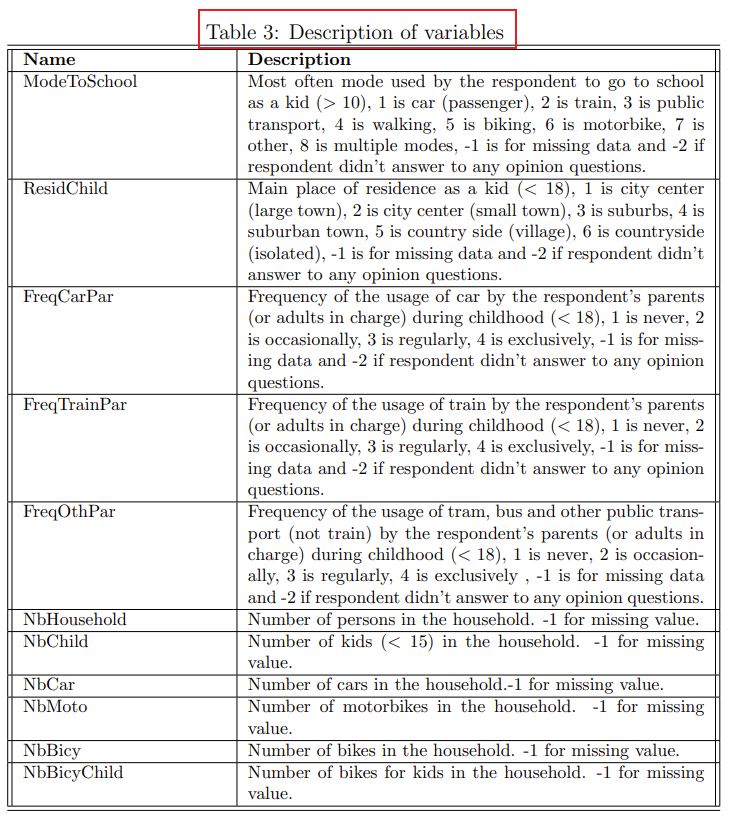
文章目录
- 聚类结果
- 一、论文内容
- 1.1 Ground Surface Removal
- 1.2 Fast Euclidean Clustering
- 题外:欧几里得聚类
- Fast Euclidean Clustering
- FEC利用具有点索引顺序的逐点方案的浅显理解
- 1.3 源码中问题说明
- 二、参考
聚类结果
原始代码中采用的是pcl中的搜索方式,替换为另外第三方库(nanoflann),速度得到进一步提升。
一、论文内容
论文中给出的结论:该方法避免了在每个嵌套循环中不断遍历每个点是产生的耗时和内存,在经典分割方法的基础上实现了两个数量级,同时产生高质量的结果。
论文给出的方法包含两步:1. Ground Surface Removal;2.The Clustering of the remaining points;
1.1 Ground Surface Removal
通过对点云进行预处理操作,论文中采用的是Cloth Simulation Filter提取和滤除接地点云;Cloth Simulation Filter具体实现过程可参考点云地面点滤波(Cloth Simulation Filter, CSF)“布料”滤波算法介绍
1.2 Fast Euclidean Clustering
题外:欧几里得聚类
- 找到空间中某点 p 11 p_{11} p11,用KD-Tree找到离他最近的 n n n个点,判断这 n n n个点到的距离。将距离小于阈值 r r r的点 p 12 , p 13 , p 14 . . . p_{12},p_{13},p_{14}... p12,p13,p14...放在类 Q Q Q里;
- 在 Q ( p 11 ) Q(p_{11}) Q(p11)里找到一点 p 12 p_{12} p12 ,重复步骤1;
- 在 Q ( p 11 , p 12 ) Q(p_{11},p_{12}) Q(p11,p12)找到一点,重复步骤1,找到 p 22 , p 23 , p 24 . . . p_{22},p_{23},p_{24}... p22,p23,p24...全部放进 Q Q Q里;
- 当 Q Q Q再也不能有新点加入了,则完成搜索了;
Fast Euclidean Clustering
论文中聚类方法与EC类似,使用欧几里得(L2)距离度量来测量无组织点云的接近度,并将相似性一致的点合并到同类中,描述如下:

- 伪代码

- 算法流程示例

FEC利用具有点索引顺序的逐点方案的浅显理解
- 搜索并给每一次搜索到的点打标签(min_tag),如果在搜索过程中存在其他打过标签的点,将其合并进来,并对全部合并的点重新以最小的标签值重新打标签,依次对所有点按顺序进行打标签,并存放在数组中;(相同标签的数量代表的是点云聚到一个类别的点数)
- 对打过标签的数组重新存放排序(排序是按照标签值进行排序),并依次循环进行点数过滤,保留阈值范围外的点云;
1.3 源码中问题说明
- 最后的点数过滤应该是不需要的
if ((i - beginIndex) >= static_cast<unsigned long>(minPointsNum)) {for (j = beginIndex; j < i; j++) {unsigned long m = 0;inliers->indices.resize(i - beginIndex);for (j = beginIndex; j < i; j++) {inliers->indices[m++] = indicesTags[j].nPointIndex;}clusterIndices.push_back(*inliers);}
}
- 不需要 Ground Surface Removal
二、参考
- FEC: Fast Euclidean Clustering for Point Cloud Segmentation
- https://github.com/YizhenLAO/FEC