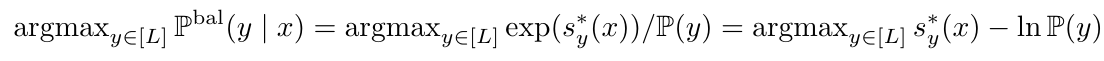biogeme-nest_logit
基础数据:
optima.dat
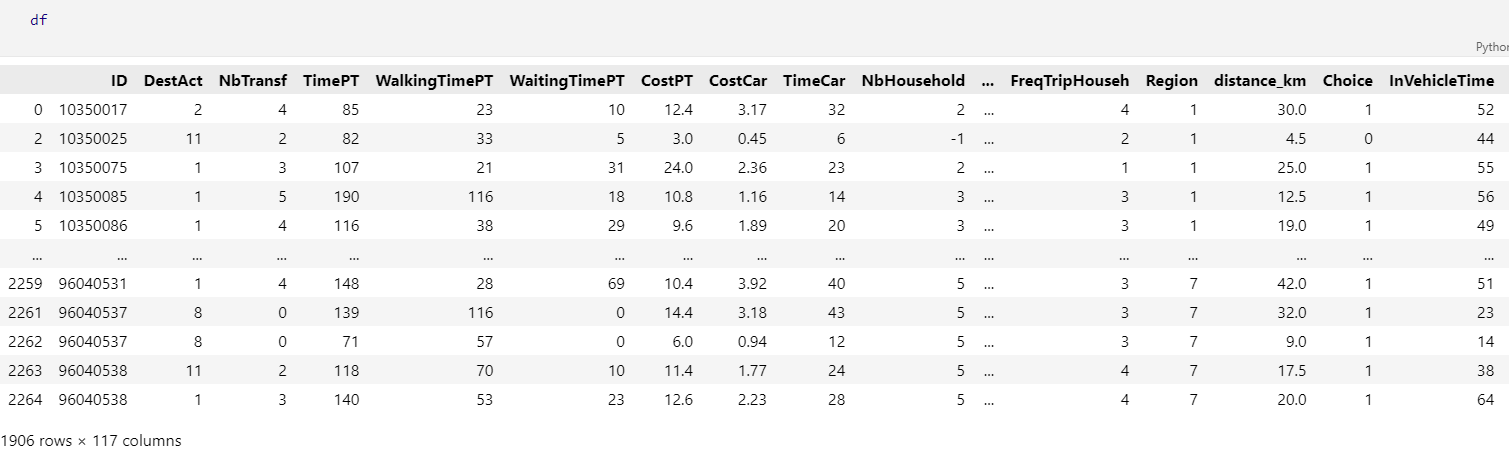
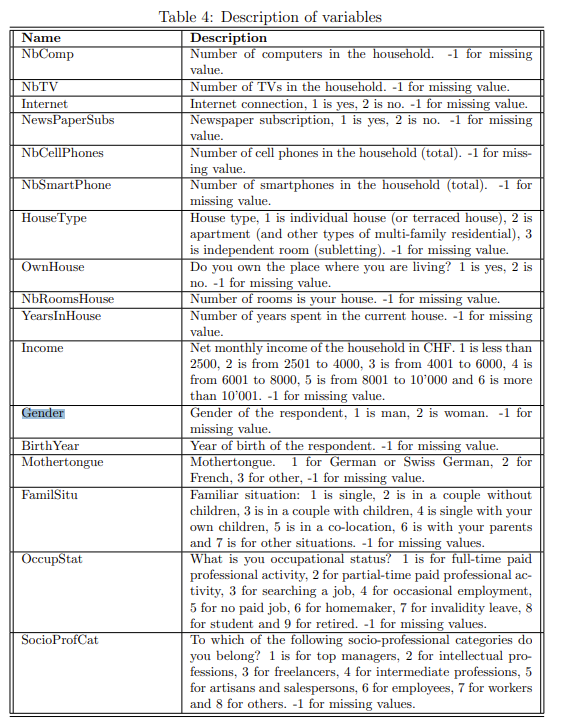
变量的描述:出处
- OccupStat:职业
- TimePT:公共交通通行时间
- TimeCar:小汽车通行时间
- MarginalCostPT:公共交通总成本
- CostCarCHF:小汽车的总汽油成本
- distance_km:距离
- choice:Choice variable: 0 = public transports (train, bus, tram, etc.); 1 = private modes (car, motorbike, etc.); 2 = soft modes (bike, walk, etc.)
- Gender:性别
-
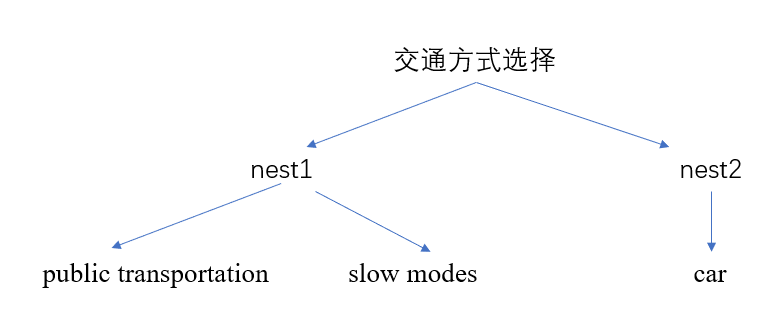
public transportation 和slow modes 被分为了一个nest
-
car单独组成一个nest
不同主枝下面可以有不同数量的分支,也可以只有一个分支
定义效用函数
三种交通方式的效用模型。这个效用函数,实质上 = 常数+时间成本+经济成本

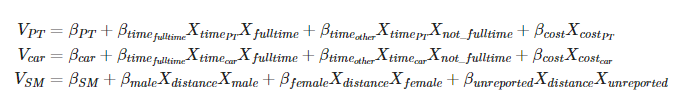
-
ASC CAR, ASC SM, BETA TIME FULLTIME, BETA TIME OTHER, BETA DIST MALE, BETA DIST FEMALE, BETA DIST UNREPORTED, BETA COST, are parameters to be estimated(是我们需要进行标定的参数)
-
TimePT scale, MarginalCostPT scaled, TimeCar scale, CostCarCHF scale, distance km scale are attributes and fulltime , notfulltime, male, female, unreportedGender are socio-economic characteristics. (其他的是社会经济变量:时间、成本、距离、性别)
-
ASC CAR, ASC SM,ASC_PT :常数项
需要注意的是:并不是所以的常数项都可以标定得到。(参考教程)
代码
(整体的代码结构参照:夜间清风-交通出行预测)
整体代码见 biogeme -02estimation.ipynb
1.导入库+读取数据库文件并创建数据库对象
# 导入库
from biogeme import models
import biogeme.biogeme as bio
from scenarios import scenario, database
import pandas as pd
import biogeme.database as db
from biogeme.expressions import Beta, Variable#读取数据
df = pd.read_csv('optima.dat', sep='\t') #dataframe
#创建数据库对象
database = db.Database('optima', df)
2. 根据数据设置变量
数据库中的每一个列名对应的模型中的一个变量。用以下语句设置变量:
Choice = Variable('Choice')
TimePT = Variable('TimePT')
TimeCar = Variable('TimeCar')
MarginalCostPT = Variable('MarginalCostPT') # 边际成本
CostCarCHF = Variable('CostCarCHF') #
distance_km = Variable('distance_km') #距离
Gender = Variable('Gender')
OccupStat = Variable('OccupStat')
Weight = Variable('Weight')
3. 设置待估计变量
# List of parameters to be estimated #待估计的参数列表
ASC_CAR = Beta('ASC_CAR', 0, None, None, 0) #Beta:从数据中估计未知参数
ASC_PT = Beta('ASC_PT', 0, None, None, 1)
ASC_SM = Beta('ASC_SM', 0, None, None, 0)
BETA_TIME_FULLTIME = Beta('BETA_TIME_FULLTIME', 0, None, None, 0)
BETA_TIME_OTHER = Beta('BETA_TIME_OTHER', 0, None, None, 0)
BETA_DIST_MALE = Beta('BETA_DIST_MALE', 0, None, None, 0)
BETA_DIST_FEMALE = Beta('BETA_DIST_FEMALE', 0, None, None, 0)
BETA_DIST_UNREPORTED = Beta('BETA_DIST_UNREPORTED', 0, None, None, 0)
BETA_COST = Beta('BETA_COST', 0, None, None, 0)
Biogeme用Beta库来定义待估参数(模型系数)。ASC CAR, ASC SM,ASC_PT :常数项。其他参数是各变量对应的系数。仔细看一下效用函数就能明白。
在定义待估计系数时,需要提供5个信息:
- 参数名称
- 参数的默认值
- 参数下限,没有用None表示
- 参数上限,没有用None表示
- 还要给参数一个标记:0表示要估计该参数;1表示保持它的默认值
4. 变量数值缩放
由于数值原因,最好将数据缩放到1左右
TimePT_scaled = TimePT / 200
TimeCar_scaled = TimeCar / 200
CostCarCHF_scaled = CostCarCHF / 10
distance_km_scaled = distance_km / 5
male = Gender == 1
female = Gender == 2
unreportedGender = Gender == -1fulltime = OccupStat == 1
notfulltime = OccupStat != 1
#OccupStat 1:表示全职 !1 :非全职
5. 定义效用函数
MarginalCostScenario = MarginalCostPT * factor
MarginalCostPT_scaled = MarginalCostScenario / 10
#定义效用函数
V_PT = (ASC_PT+ BETA_TIME_FULLTIME * TimePT_scaled * fulltime+ BETA_TIME_OTHER * TimePT_scaled * notfulltime+ BETA_COST * MarginalCostPT_scaled
)
V_CAR = (ASC_CAR+ BETA_TIME_FULLTIME * TimeCar_scaled * fulltime+ BETA_TIME_OTHER * TimeCar_scaled * notfulltime+ BETA_COST * CostCarCHF_scaled
)
V_SM = (ASC_SM+ BETA_DIST_MALE * distance_km_scaled * male+ BETA_DIST_FEMALE * distance_km_scaled * female+ BETA_DIST_UNREPORTED * distance_km_scaled * unreportedGender
)
6. 对应效用函数与方案
V = {0: V_PT,1: V_CAR, 2: V_SM}
V: 代表各备选方案的效用函数的字典
7. 定义nest结构(分层结构)
MU_NOCAR = Beta('MU_NOCAR', 1.0, 1.0, None, 0)CAR_NEST = 1.0, [1] # car单独分为一类 nest:CAR_NEST
NO_CAR_NEST = MU_NOCAR, [0, 2] # PT、SM分为一类 nest:NO_CAR_NEST
nests = CAR_NEST, NO_CAR_NEST
8. 计算logprob(概率的对数)
logprob = models.lognested(V, None, nests, Choice) #V是效用函数
#需要输入1. 各备选方案的效用函数字典 2. 各方案可用性字典(可以为None)
#3. nests:tuple
"""Example::nesta = MUA, [1, 2, 3]nestb = MUB, [4, 5, 6]nests = nesta, nestb
"""
#logprob:基于MEV,对嵌套logit模型的选择概率取log
9. estimation
# Create the Biogeme object for estimation #估计
biogeme = bio.BIOGEME(database, logprob)
biogeme.modelName = '02estimation'print('Estimation...')
# Estimate the parameters. Perform bootstrapping.
#估计参数
results = biogeme.estimate(bootstrap=100)# Get the results in a pandas table
pandasResults = results.getEstimatedParameters()
print(pandasResults)
10. Simulation
print('Simulation...')simulated_choices = logprob.getValue_c(betas=results.getBetaValues(), database=database
)
#getValue_c ,如果提供了一整个数据库,则返回的是一个list,是将表达式应用到每一行的一个结果(概率值,浮点数)
#getValue_c()函数中需要输入上面标定的参数+数据库print(simulated_choices)loglikelihood = logprob.getValue_c(betas=results.getBetaValues(), #标定系数值database=database, #数据库aggregation=True, #如果一共了一个database,且参数为true,则表达式应用于每个条目(行),并聚合所有值,返回和。
)print(f'Final log likelihood: {results.data.logLike}')
print(f'Simulated log likelihood: {loglikelihood}')
结果
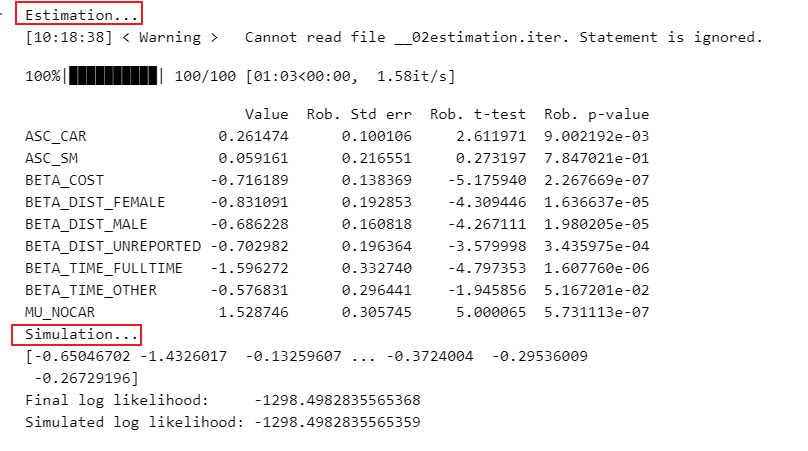
整体代码
#%%
"""File scenarios.py:author: Michel Bierlaire, EPFL
:date: Sun Oct 31 09:40:59 2021Specification of a nested logit model, that will be estimated, andused for simulation. Three alternatives: public transporation, carand slow modes. RP data.三种选择方式:public car 慢速模式Based on the Optima data.It contains a function that generates scenarios where the currentcost of public transportation is multiplied by a factor.包含一个函数,生成当前公共交通成本*一个因素"""import pandas as pd
import biogeme.database as db
from biogeme.expressions import Beta, Variable
from biogeme import models
import biogeme.biogeme as bio
from scenarios import scenario, database# Read the data
df = pd.read_csv('optima.dat', sep='\t')
database = db.Database('optima', df)# Variables from the data #设置变量
Choice = Variable('Choice')
TimePT = Variable('TimePT')
TimeCar = Variable('TimeCar')
MarginalCostPT = Variable('MarginalCostPT') # 边际成本
CostCarCHF = Variable('CostCarCHF') #
distance_km = Variable('distance_km') #距离
Gender = Variable('Gender')
OccupStat = Variable('OccupStat')
Weight = Variable('Weight')# Exclude observations such that the chosen alternative is -1
database.remove(Choice == -1.0)# Normalize the weights (规范化权重)
sumWeight = database.data['Weight'].sum()
numberOfRows = database.data.shape[0] #行数
normalizedWeight = Weight * numberOfRows / sumWeight# List of parameters to be estimated #待估计的参数列表
ASC_CAR = Beta('ASC_CAR', 0, None, None, 0) #Beta:从数据中估计未知参数
ASC_PT = Beta('ASC_PT', 0, None, None, 1)
ASC_SM = Beta('ASC_SM', 0, None, None, 0)
BETA_TIME_FULLTIME = Beta('BETA_TIME_FULLTIME', 0, None, None, 0)
BETA_TIME_OTHER = Beta('BETA_TIME_OTHER', 0, None, None, 0)
BETA_DIST_MALE = Beta('BETA_DIST_MALE', 0, None, None, 0)
BETA_DIST_FEMALE = Beta('BETA_DIST_FEMALE', 0, None, None, 0)
BETA_DIST_UNREPORTED = Beta('BETA_DIST_UNREPORTED', 0, None, None, 0)
BETA_COST = Beta('BETA_COST', 0, None, None, 0)# Definition of variables: 定义变量
# For numerical reasons, it is good practice to scale the data to
# that the values of the parameters are around 1.0.
# 由于数值原因,最好将数据缩放到1左右TimePT_scaled = TimePT / 200
TimeCar_scaled = TimeCar / 200
CostCarCHF_scaled = CostCarCHF / 10
distance_km_scaled = distance_km / 5
male = Gender == 1
female = Gender == 2
unreportedGender = Gender == -1fulltime = OccupStat == 1
notfulltime = OccupStat != 1
#OccupStat 1:表示全职 !1 :非全职# def scenario(factor=1.0):
"""Provide the model specification for a scenario with the price ofpublic transportation is multiplied by a factor:param factor: factor that multiples the price of public transportation.
:type factor: float:return: a dict with the utility functions, the nesting structure,and the choice expression.返回的是一个字典,包含效用函数,嵌套结构,选择表达式:rtype: dict(int: biogeme.expression), tuple(biogeme.expression,list(int)), biogeme.expression
"""
factor = 1.0
MarginalCostScenario = MarginalCostPT * factor
MarginalCostPT_scaled = MarginalCostScenario / 10
# Definition of utility functions:
V_PT = (ASC_PT+ BETA_TIME_FULLTIME * TimePT_scaled * fulltime+ BETA_TIME_OTHER * TimePT_scaled * notfulltime+ BETA_COST * MarginalCostPT_scaled
)
V_CAR = (ASC_CAR+ BETA_TIME_FULLTIME * TimeCar_scaled * fulltime+ BETA_TIME_OTHER * TimeCar_scaled * notfulltime+ BETA_COST * CostCarCHF_scaled
)
V_SM = (ASC_SM+ BETA_DIST_MALE * distance_km_scaled * male+ BETA_DIST_FEMALE * distance_km_scaled * female+ BETA_DIST_UNREPORTED * distance_km_scaled * unreportedGender
)# Associate utility functions with the numbering of alte1rnatives
#将效用函数和方案编号联系起来
V = {0: V_PT, 1: V_CAR, 2: V_SM}# Definition of the nests:
# 1: nests parameter 嵌套系数
# 2: list of alternatives #备选列表
MU_NOCAR = Beta('MU_NOCAR', 1.0, 1.0, None, 0)CAR_NEST = 1.0, [1] # car单独分为一类 nest:CAR_NEST
NO_CAR_NEST = MU_NOCAR, [0, 2] # PT、SM分为一类 nest:NO_CAR_NEST
nests = CAR_NEST, NO_CAR_NEST# return V, nests, Choice, MarginalCostScenario
# The choice model is a nested logit, with availability conditions
# For estimation, we need the log of the probability
# log(prob) :概率的对数
logprob = models.lognested(V, None, nests, Choice) #V是效用函数 # Create the Biogeme object for estimation #估计
biogeme = bio.BIOGEME(database, logprob)
biogeme.modelName = '02estimation'print('Estimation...')
# Estimate the parameters. Perform bootstrapping.
results = biogeme.estimate(bootstrap=100)# Get the results in a pandas table
pandasResults = results.getEstimatedParameters()
print(pandasResults)print('Simulation...')simulated_choices = logprob.getValue_c(betas=results.getBetaValues(), database=database
)print(simulated_choices)loglikelihood = logprob.getValue_c(betas=results.getBetaValues(),database=database,aggregation=True,
)print(f'Final log likelihood: {results.data.logLike}')
print(f'Simulated log likelihood: {loglikelihood}')附:变量说明
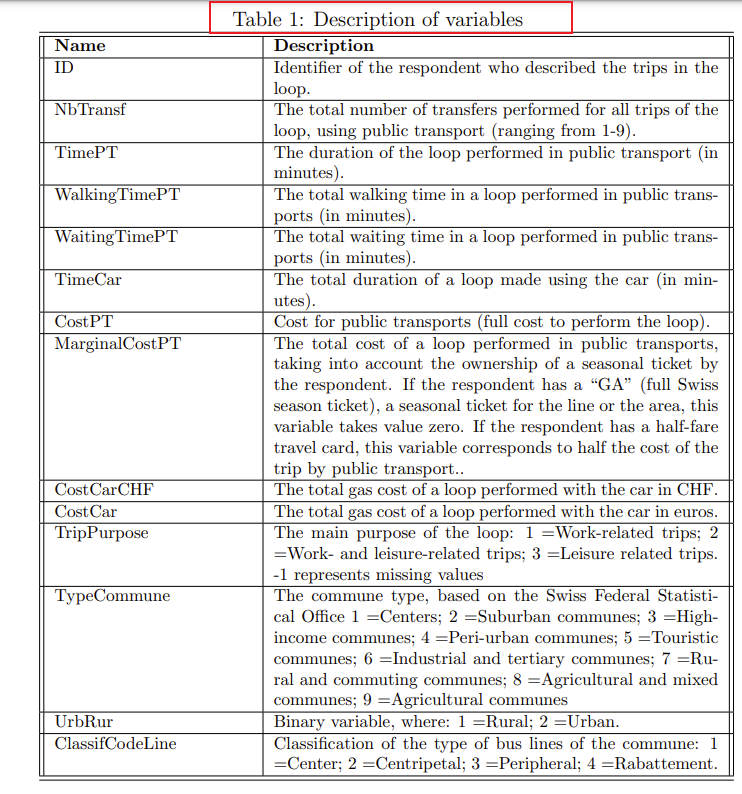
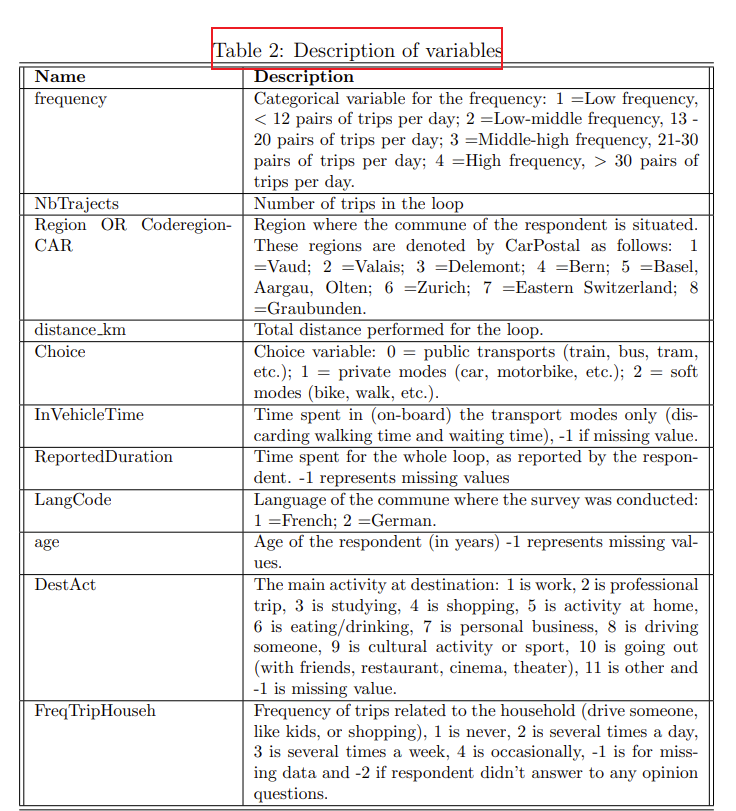
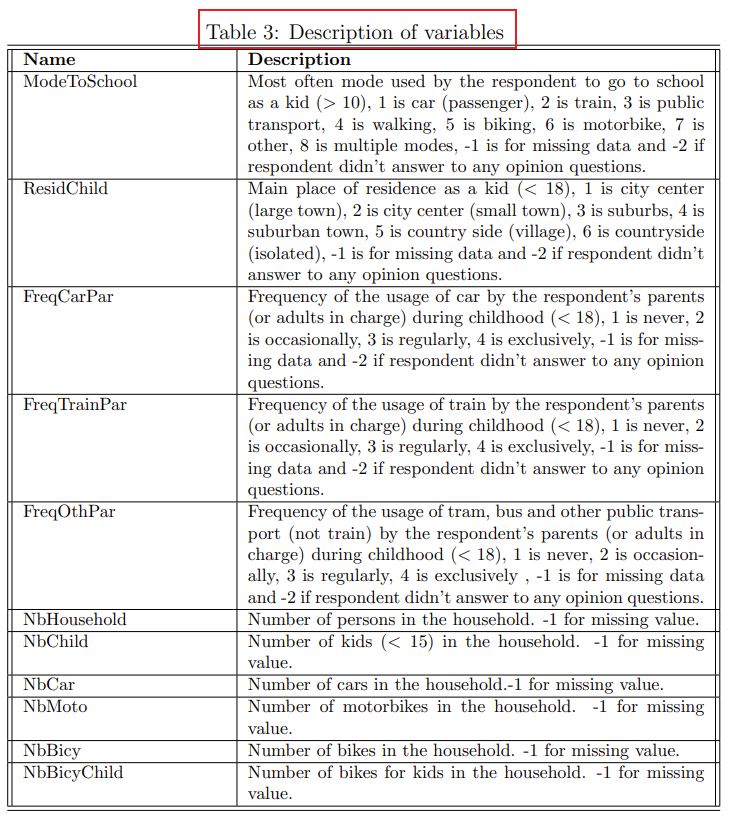
ase
)
print(simulated_choices)
loglikelihood = logprob.getValue_c(
betas=results.getBetaValues(),
database=database,
aggregation=True,
)
print(f’Final log likelihood: {results.data.logLike}‘)
print(f’Simulated log likelihood: {loglikelihood}’)
# 附:变量说明 [外链图片转存中...(img-cujmPN3m-1664885232398)][外链图片转存中...(img-7srFLeKO-1664885232399)][外链图片转存中...(img-Y5Vs20FO-1664885232399)]